Consider consuming a series of bytes and storing them in memory for future processing. Let’s take the code snippet below:
const int noNumbers = 10000000; // 10 mil
ArrayList numbers = new ArrayList();
Random random = new Random(1); // use the same seed as to make
// benchmarking consistent
for (int i = 0; i < noNumbers; i++)
{
int currentNumber = random.Next(10); // generate a non-negative
// random number less than 10
numbers.Add(currentNumber); // BOXING occurs here
}
Is this code good from a performance standpoint ? Not really, it’s actually quite appalling. Take a look at the running times for the ArrayList snippet above and, for the same exact code, but which uses List instead:
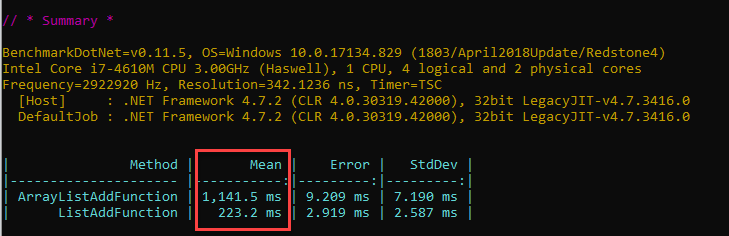
This makes the ArrayList code more than 5 times slower than the List one.
Boxing happens in the first case, but not in the second. This mechanism explains most of the performance difference seen above. Intrigued ? Read on.
Round 1
We’ll start by defining what boxing is, then look at the notions of value and reference types and go over some conceptual animations for both value and reference types. Next, several examples of value/reference types will be looked at and how to identify each, describe where each type is stored, see what value/reference types actually look like in practice, and how can their location be identified. Then we’ll move on to a simple example showing boxing and based on this, delve into a conceptual animation and a debugger video, describe the steps involved in boxing, present what’s the reason for boxing to exist and ways of identifying when boxing occurs. Finally, we’ll wrap up with a series of Q&A.
Let’s look at some definitions for the boxing concept, as defined in some of the best C# books around:
Boxing is the act of converting a value-type instance to a reference-type instance.
Joseph Albahari, Ben Albahari. C# 7.0 in a Nutshell: The Definitive Reference
[…]C# and .NET provide a mechanism called boxing that lets you create an object from a value type value and use a reference to that new object.
Jon Skeet. C# in Depth, Third Edition
ECMA-335 – the standard defining the CLI (Common Language Infrastructure) has this to say about boxing:
The box instruction is a widening (always type-safe) operation that converts a value type instance to System.Object by making a copy of the instance and embedding it in a newly allocated object.
ECMA-335
Now if you’re like me and you’re also getting up to speed with C#, the definitions above might not be the key to instant understanding. Particularly the last one is somewhat hard to picture in one’s head.
One thing is certain – they all entail the notions of value and reference type. As we will see later, they have key implications further down the line, so let’s review these concepts now.
Value Meets Reference
Enter Microsoft’s article here, which goes to say that:
A variable of a value type contains a value of the type. For example, a variable of the
inttype might contain the value42. This differs from a variable of a reference type, which contains a reference to an instance of the type, also known as an object.
To capture the difference between value and reference types, we’ll use 2 instances of each, and run through the following set of steps twice – once for a value type, then for a reference one:
- create a variable of the designated type and assign it a value
- create a second variable of the same type and assign it the first variable defined above
- assign a new value to the second variable
- check both variables for the values they now contain
For each animation, you’ll see the code being executed to the right, with each new instruction ran highlighted in turn. To the left a diagram will show what happens conceptually at every stage.
Let’s see what happens for a value type (int):
The code is extremely simple. You can see everything is neatly separated on the diagram – the variables don’t share anything, aside the type used to instantiate them. Changes against one don’t impact the other.
Now let’s see how reference types behave, by taking the case of a simple ArrayList, and running through the same identical steps as before:
The code is simple, but let’s go through each instruction:
- Step 1: (ArrayList one;) A reference type variable of type
ArrayListis created. It points to nothing at this stage. - Step 2: (one = new ArrayList();) 2 things occur: a new object of type
ArrayListis created somewhere in memory, and variableoneis made to point at that address+ location - Step 3: (one.Add(“blue”);) The string “blue” is added to the empty
ArrayListobject in memory - Step 4: (ArrayList two;) A new reference type variable of type
ArrayListis created. Just like the first one, it points to nothing yet. - Step 5: (two = one;) Variable
twois made to point at the same object instanceoneis pointing to. - Step 6: (two.Add(“red”);) The string “red” is added to the
ArrayListobject in memory, that already contains “blue“.
As the animation also shows, this time there’s no second instance of the type – there’s no second ArrayList that gets created for two. Instead both variables are now pointing at the same original object. Thus both can be used as a sort of “handle”, to operate against the same object. What the 2 variables share is only the reference to the instance of the object. Since they’re both pointing at the same thing, whatever one variable is used to perform an action against the ArrayList object, the other one will reflect it as well.
So what goes on when value type variables and reference type variables are passed around, say as parameters of a method ? It’s simple – the value of the variable is copied, and the method gets to operate on that copy.
“But objects don’t get copied when being passed to a method !” I rightfully hear you objecting. The objects themselves don’t get copied, but remember what a variable representing a reference type actually contains. It simply stores inside a reference, an address+ where the object itself is found in memory. When passed as a parameter to a method, it’s this address that gets copied and made available to the method itself. You can do whatever you want to that copy of the address, up to destroying it – which actually happens when the method returns – however the original address, and thus its link to the object it points to stays very much the same.
The very same exact thing happens when a value type variable is used as parameter to a method. The contents of that variable – in this case the instance of the variable itself – will be copied and passed along to the method. Same as before, the method can do whatever it wants to the value of the parameter passed – it won’t affect the original value type instance in any way.
Now it should be pretty obvious why one type is called value, and the other reference. Simply because when assigning a value type variable to another value type variable (as in a = b) the copying is done by value, while for a reference type variable being assigned to another reference type variable, it’s done by reference.
Which is Which ?
Given a specific type, how can you tell if it’s a value or reference type ?
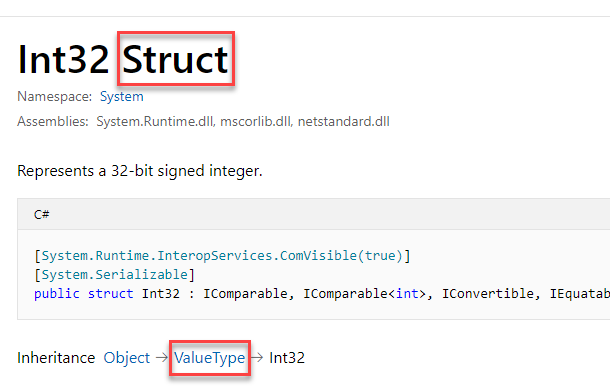
Structures (declared using struct) and enumerations (declared using enum) are value types. If you take a look at the Microsoft page that describes a specific type, you get to find out pretty quickly if it’s a value type. Another giveaway for value types is that they inherit from ValueType. Take a look at the page for Int32 here:
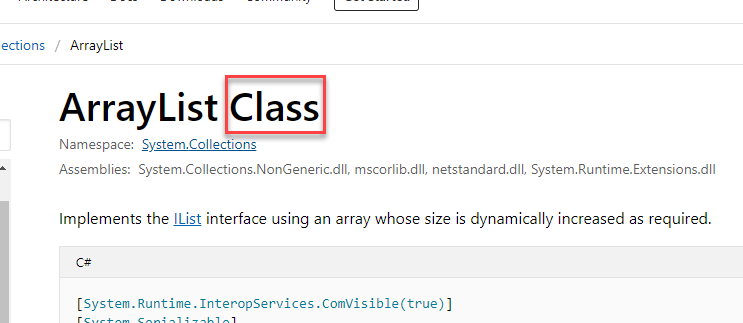
Reference types, on the other hand, will include all classes. On the ArrayList‘s Microsoft page here, note the clear designation:
Delegates (declared using delegate), interfaces (declared using interface) and arrays are also reference types. For arrays – pay special attention that even if the elements within are instances of value types (eg int[]), the array itself is of type reference.
Which Goes Where ?
In our discussion so far the variables and the type instances were perched somewhere on the blackboard. It’s quite natural that they’ll be stored somewhere in memory. But we’ll have to get more specific about exactly where in memory do all these live.
Usually* there are 2 locations where type instances are stored – the stack and the heap.
The stack is where you’ll mainly** get to see local variables stored. Should that local variable represent a value type instance (eg int i declared within a method) then that will go to the stack.
The heap is always the place where reference type instances are stored in C#. Note that an object instance field that’s of a value type (eg the memory for int j declared within a class) will be allocated on the heap, along with the rest of the components of that object.
In the animation above showing reference types, the instance of ArrayList is actually stored on the heap.
There are other languages (eg C++) where you can decide where you want to place a new instance of a specific type (value or reference), but in C# the language pretty much chooses for you.
Proof
Ok, a lot of talk so far, but nothing concrete. Let’s put the code we’ve previously went through as part of the simple blackboard animations in Visual Studio and run this for real. The memory window debug feature will be used in order to get a glimpse of what sits in memory at every step of the road. On the right-hand side you’ll get to see what goes on conceptually as the code on the left is stepped into.
Value types first:
There are only 2 consecutive locations on the stack used to store the actual content of our ints. Just as expected, each variable contains directly its respective value.
The a = b instruction’s effect looks deceptively simple. After all, it’s just a 5 that gets copied across. Don’t let yourself fooled though – if a and b would have been instances of a struct with multiple fields, then all that data would have been copied across.
Last and not least – note that the heap never gets touched.
Now let’s turn to reference types:
The outcome looks almost the same initially: 2 consecutive locations on the stack are used. Only that this time both contain an address pointing to the instance of the actual object. The instance itself contain additional metadata, signified by the horizontal and vertical dots within the memory locations on the heap.
The two = one instruction, the equivalent of our previous b = a, this time actually results in just the address of the object’s instance being copied across.
And once the strings "blue" and "red" get added to the ArrayList, instead of the letters you get to see yet another reference to different locations on the heap where the string objects are actually stored. Which is to be expected – after all, the string type is a reference one.
As for the strings themselves, there’s also metadata where these instances are stored too. The number of letters (highlighted in the last animation in red at 1:26 and 2:01 respectively) for each string is also stored in there. The actual letters (highlighted in green towards the end of the animation) making up the strings are just a subset of the data.
Ok, but how do you tell which memory address is within the stack, and which is contained in the heap ? The right hand side blackboard diagram shows them neatly separated, but where’s the info to back it up ?
There are multiple ways to double-check this is so. One is to simply use VMMap and find the address you’re after. Since VMMap shows the stack and the managed heap separately, it’s rather straightforward.
First, let’s look at the value type example (int), where we’re only dealing with 2 addresses, that of a and b:
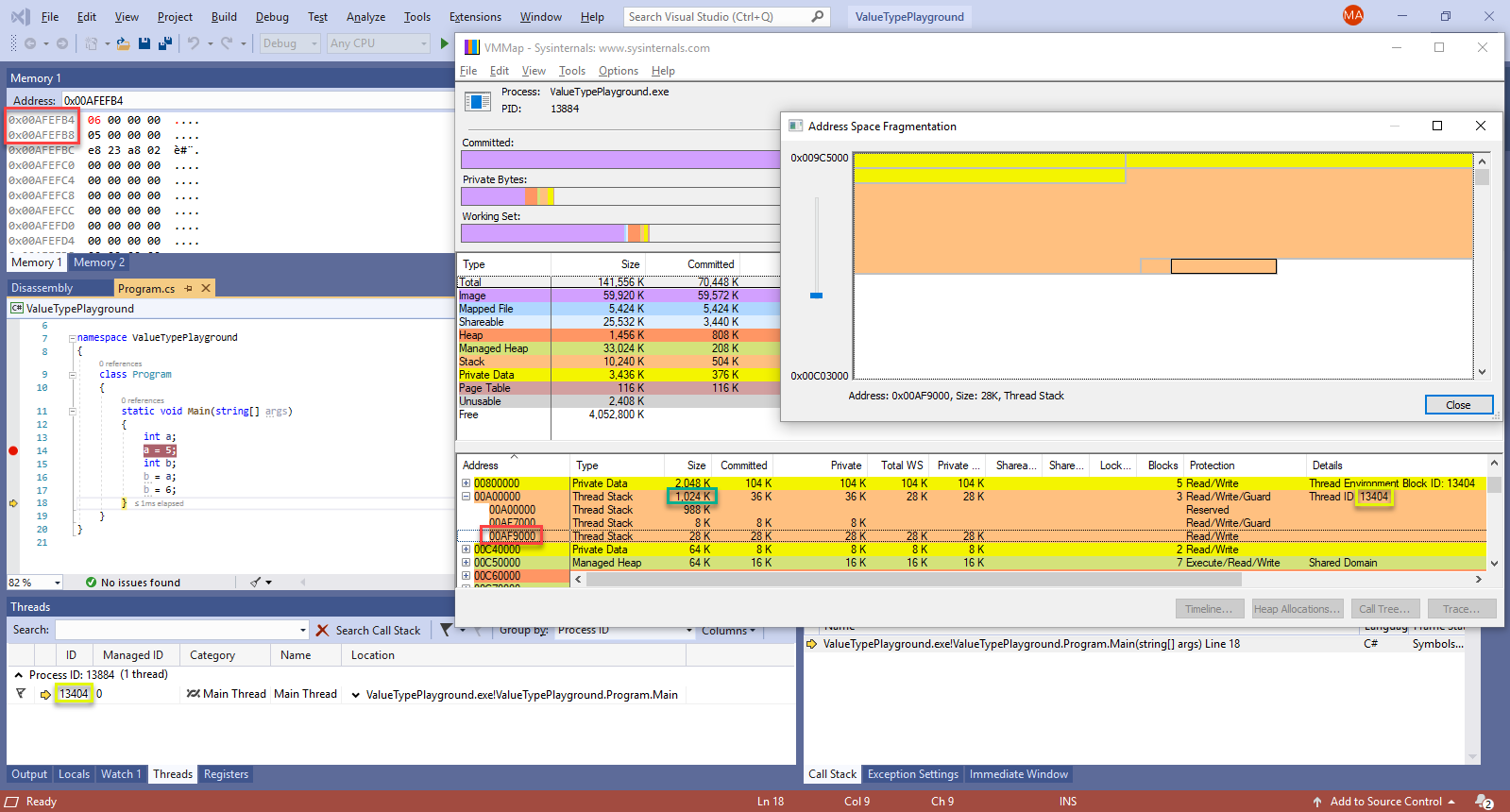
Both variables’ addresses are highlighted in red in the top left. Searching through VMMap’s address ranges, the one containing both our addresses can be seen – also highlighted in red. The 2nd column, labelled “Type”, shows that this address space belongs to a stack.
(If you want to double-check that the addresses for a and b are within the address range highlighted, think that 0x1000 = 4K. So based on the block size of 28K, the range covered is 00AF9000 – 00AFFFFFF).
Since by default each thread gets assigned a 1 MB stack – each consisting of a contiguous block of memory -, we also need to check that the thread whose stack we’re seeing is actually the one running our code. The highlights in yellow – in Visual Studio’s “Threads” window, as in VMMap’s “Details” column, confirm that it’s the same thread (13404).
For the reference type example (ArrayList), we have to check where the 2 addresses of the variables (one and two) live, as well as the memory locations pointed to by their content. The variables first:

Same as before, we can see the address range containing both variable addresses identified as “Thread Stack” for the thread that’s running our code. The highlight on the top left only shows variable one, but two is only 4 bytes away (and fitting in that same range).
For the address of the object’s instance:
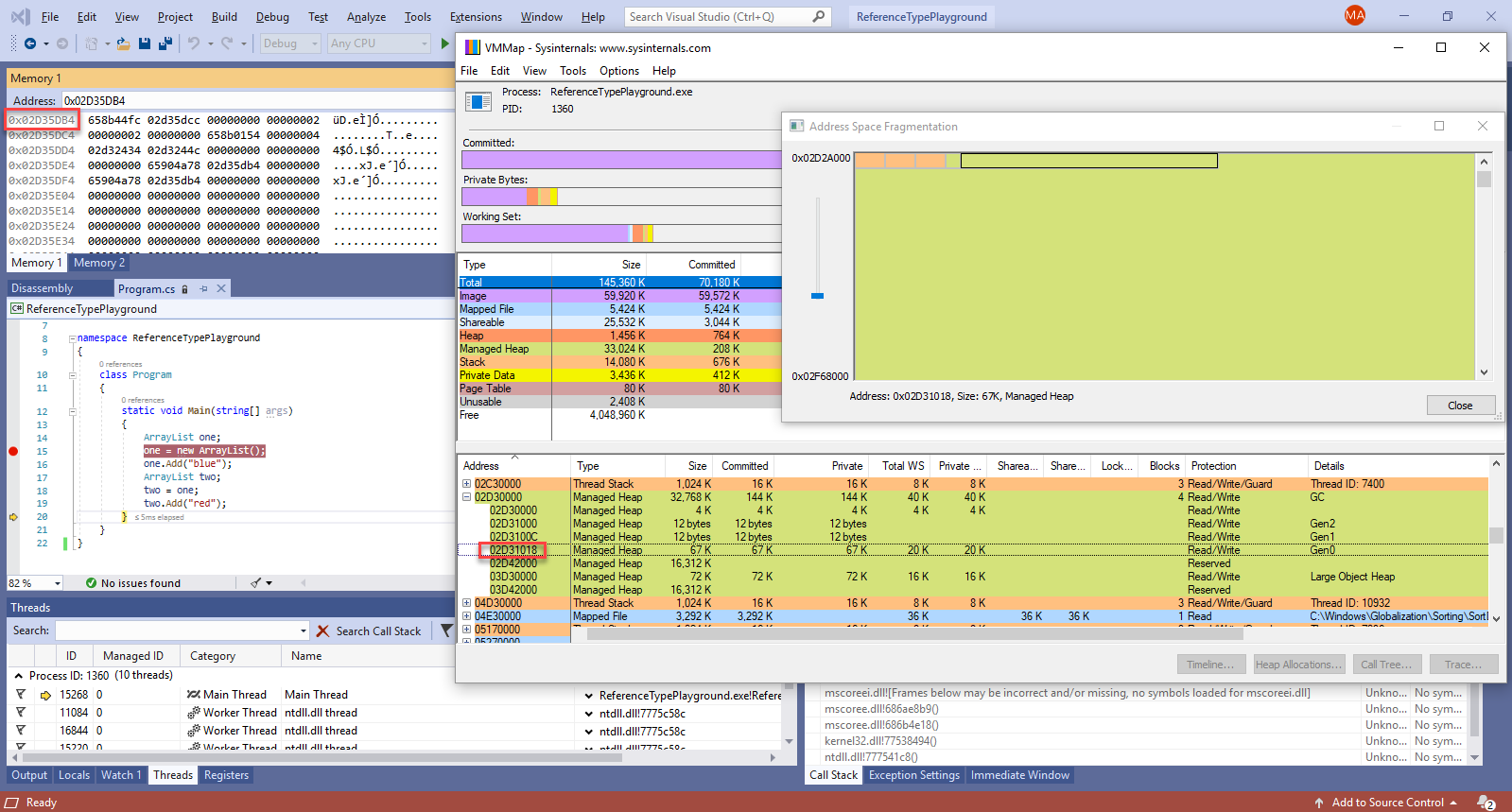
We can see that indeed the memory range used for the ArrayList instance is in the heap. Note that this time there’s only one managed heap (as by default there’s only one allocated per process).
As for the strings themselves ("red" and "blue"), being instances of a class, they’re also found on the heap. You can actually cross-check that the addresses are within the range highlighted in the previous picture.
Another way of getting to know which one is a value type instance, and which is a reference type one is to be aware of the following:
Every object on the heap requires some additional members—called the type object pointer and the sync block index—used by the CLR to manage the object.
Jeffrey Richter. CLR via C#
The type object pointer is a reference to the type object itself, in other words the type’s “blueprint” – the data structures used to represent the type -, as it’s kept by the CLR. So for an an ArrayList object this will point to where the CLR created the corresponding data structures for the ArrayList type, for a string it will point to where the data structures for string are, and so forth.
If you look back at figure 3 (the only one with VMMap and the managed heap highlighted) you can see the type object pointer for ArrayList being stored at exactly the location the reference type variable is pointing to: 0x02D35DB4. The type object pointer’s value is 658b44fc. In the latest reference type animation, at 1:24 you can see the type object pointer for string: 658afd60. This is used for both string objects that are used to store "red" and "blue".
The value types don’t have such additional info. They simply contain the bare data. Which in turn makes differentiating between a value type instance and a reference type one pretty simple, if one has access to a debugger that is.
Round 2
Now the definitions given previously should start to make more sense.
Let’s take a really simple boxing example:
int a = 5;
object o = a;
Simple enough, yet the last line seems a bit awkward: a value type variable is assigned to a reference type one. We did consider value-to-value and reference-to-reference assignments earlier, but how does this one work ?
Let’s see how this sample looks conceptually. The assignments and declarations are broken apart in the animation, so things are more clear.
The whole “magic” happens in the very last line, namely:
- Memory is allocated, large enough to hold the value type variable
i‘s content - The content of the value type variable
iis copied across to the newly allocated memory - A reference to the newly allocated object is returned and stored within
o
Let’s look at how the code runs with the help of the debugger.
Unlike the reference type debugger video, there’s no more dots placed at the beginning of the memory portion occupied by the object’s instance on the heap, to signal metadata. We now know that the thing pointed by the address within the reference type variable is the type object pointer (highlighted in blue in the video). The int value itself follows as the next 4 bytes (highlighted in green).
We’ve started with a value type variable (i), and ended up with a reference type one (o) pointing to a full-fledged object instance – essentially what boxing is supposed to do.
Note that once boxed, the new object keeps no link whatsoever with the value type instance it was created from. Modifying either one will not affect the other.
Why Bother ?
But why all this struggle, of converting to object ? All that copying happening, all those references created – why go to this trouble after all ? Well, it turns out that some methods only accept parameters of type object. One of them is ArrayList‘s Add:
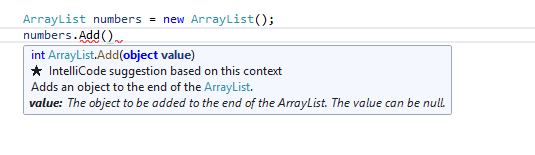
Assume you want to add an int to an ArrayList instance. The only way of doing this is to call the Add method. But there’s no overload that takes int as a parameter, just the one that takes object. So you pass the int to the method as is. The code will compile just fine and work as expected, however we know that getting from a value type (int) to a reference type (object) is done through boxing.
There’s no specific instruction in C# to perform boxing. There’s no cast of any kind required. The operation happens silently, behind the scenes.
But how can one tell whether boxing occurs in the C# code after all ? Of course one can analyze the whole code at a high level and understand when this occurs. But one more foolproof way of doing it is to look at the resulting IL code.
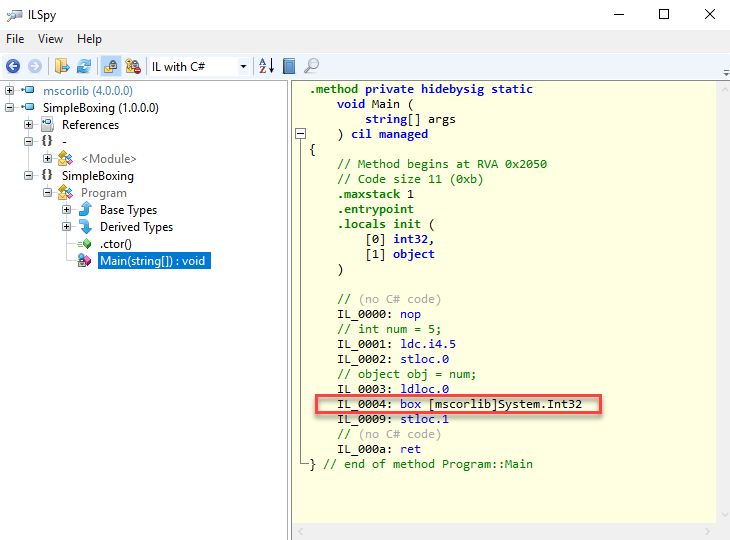
Being managed code, the instructions in C# get compiled to IL (Intermediate Language) code. IL is – as “CLR via C#” points out – “object oriented machine language“. It has its own instruction language set and among it there’s an instruction dedicated for performing the boxing mechanism, aptly named box.
An IL disassembler will show the IL code within an assembly – just look below at ILSpy ran against the simple code we used to illustrate boxing. The box instruction can be clearly seen:
How do you know beforehand if the method you’re going to call is going to box your parameters or not ? Let’s see what “CLR via C#” says about this in the context of the FCL (Framework Class Library):
If you call a method that does not have an overload for the specific value type that you are passing to it, you will always end up calling the overload that takes an Object.
Jeffrey Richter, CLR via C#
Take Console.WriteLine(i), where i is an integer. Calling this won’t result in boxing since among the multiple overloaded methods for it there’s a specific one that takes an int as parameter. When this method is called, the value of i is copied to the int parameter variable and the method executes.
That rounds up what we proposed to discuss in this first part about boxing. We’ll finish up with a session of Q&A. In the next article, we’ll look into the inner workings of the ArrayList sample, and delve into the performance details.
Q & A
Q: What do you mean by “Usually* there are 2 locations where type instances are stored – the stack and the heap” ?
A: Keep in mind that the C# language specification doesn’t say anything about heap or stack (aside from the stackalloc keyword used to allocate memory from the stack in an unsafe context). Particularly, when explaining value and reference types, there’s no talk about any stack or heap as the locations where their variables and instances are stored. “But I’d like to understand how things work under the hood. How else can I fine-tune my code if I don’t know the internals ?” By all means, look into how things work. The behavior can be observed (eg with a debugger) and read about (Jeffrey Richter’s “CLR via C#“, that looks at the main platform when the book was written: Windows), but what the C# language specs and Eric Lippert’s articles (here and here) try to send across is avoid wrong assumptions on the part of the programmer: just because you’re spotting a local variable being created on the stack on a specific version of .NET on a specific OS running on a specific hardware doesn’t mean that this will stay the same in the future. Since the C# compiler is free to choose whatever way to produce the output code, as long as it remains within the confines of the language specs, it can store that local variable on a stack, heap, cpu register (“everyone forgets about registers“) or whatever storage location/construct it deems suitable. Therefore the discussion about the stack and the heap presented in this blog post applies to what’s currently observed on a .NET Framework running on Windows. This doesn’t mean that this will apply to any combination of underlying OS, hardware and .NET version. There could be OSes that might not even provide a stack or heap to your running process. It could also be that future versions of .NET will use a different storage mechanism, that might be deemed more efficient at the time. If there wasn’t for performance implications – which we’re interested in this post – where exactly are the type instances stored would be of little interest.
Interestingly enough, neither does C’s language specifications go into any detail about the “stack” and the “heap”, with the 2007 draft having exactly 0 instances of either word within.
Q: What do you mean by “The stack is where you’ll mainly** get to see local variables stored” ?
A: John Skeet’s “C# in Depth (3rd Edition)” states that “Local variable values are always stored on the stack“, however the note right besides it reads “This is only totally true for C# 1. You’ll see later that local variables can end up on the heap in certain situations in later versions” plus the section this is under is concerned specifically with C# 1.0. In a Stack Overflow thread, Eric Lippert goes on to comment: “Not all local variables are on the stack. Closed over locals are not on the stack. Locals in iterator blocks are not on the stack. Locals in async methods are not on the stack. Enregistered locals are not on the stack. Elided locals are not on the stack. Stop believing that locals go on the stack; it’s simply false. Locals are called locals because their names have local scope, not because they are stored on the stack“.
Q: Are references always implemented using addresses in C# ?
A: On a .NET Framework running on Windows, the implementation has references actually using memory addresses under the hood. Yet on a different implementation, one no longer has this guarantee, and a reference might not be an address anymore. Eric Lippert has a very good article here, which contains the key: “[…]we do not describe references as addresses in the specification. The spec just says that a variable of reference type “stores a reference” to an object, and leaves it completely vague as to how that might be implemented“. And the specification of the C# language (ECMA 334) does indeed mention that, as you can check here.
Q: Throughout your animations, you’re using the & operator against reference types. That’s illegal !
A: Let’s see what ECMA-334 – which is the specification of the C# language – has to say about the & operator:
The & operator permits the address of a fixed variable to be obtained without restrictions.
As for the term “fixed variable” itself:
Fixed variables reside in storage locations that are unaffected by operation of the garbage collector. (Examples of fixed variables include local variables, value parameters, and variables created by dereferencing pointers). On the other hand, moveable variables reside in storage locations that are subject to relocation or disposal by the garbage collector. (Examples of moveable variables include fields in objects and elements of arrays.)
So using & against the int variables we’ve declared within the various code snippets is legal – them being local variables – but using it against reference types is not. The reason is that the GC (Garbage Collector) is free to move non-fixed variables as it sees fit. And object instances will always be allocated on the heap, therefore they are fair game for the GC. Just because you see the location of an instance of a reference type at this very moment doesn’t mean that it’ll be there in the next. GC might kick in and move your object to a different memory region, and you might be stuck tracking a “phantom” which used to be a previous version of your object. Take the very first code snippet – if one runs it for just a few scores of iterations, you might just cross paths with the GC, and unless you specifically check the address of the object at every debugging step, you could very well look at a memory location that no longer contains your current object, but a past version, as described above. Since the GC only operates against the heap, variables stored on the stack aren’t affected.
So in a way a hack is employed to look at how the object instances are stored in memory, and we get away with it simply because the GC is not triggered. And it doesn’t get triggered because 1) the snippets analyzed were short enough 2) the debugger pauses the run after each instruction 3) we got lucky. Note that this works only within the debugger, and to be more specific – the Windows version of VS 2019. If you try this within the VS 2019 Mac edition, the debugger will throw Expression not supported.
For further info refer to this and this SO threads.
Q: If the new keyword is used, is that a clear sign of a reference type being used ?
A: No. You can very well define a value type using new. It’s the name of the type itself that tells you whether you’re dealing with a value type or a reference one. See Which is Which ?
Q: How about an array of ints defined as a local variable ? Where will this get stored ?
A: It will be stored on the heap, not on the stack, despite containing instances of a value type. As per “CLR via C#“: “arrays are always reference types that are allocated on the managed heap and that your application’s variable or field contains a reference to the array and not the elements of the array itself.”
Q: But what about the fact that C# passes around objects by reference by default ?
A: That’s just bad terminology. Jon Skeet expands on this in his book “C# in Depth (3rd Edition)” in section named “Myth #3: Objects are passed by reference in C# by default” (note that only the 3rd edition has this, the 4th one doesn’t). He also has an article about this here.
Q: I’ve read about something called “free store”. Is this similar to “heap” ?
A: This thread’s accepted answer has 2 comments, of which the second actually points to a presentation by Stroustrup which indicated that the 2 notions are actually similar. This thread actually has a link to Stroustrup’s direct reply on the topic, where it’s stated that from the standpoint of actual implementation, it’s pretty much the same thing.
Q: Are the stack and heap 4-bytes wide each ? Your videos showing the Visual Studio debugger seem to suggest that.
A: No. 4 bytes was chosen in order to match the formatting of Visual Studio’s Memory tab. Since all the samples targeted 32-bit code, this allowed a group of 4 bytes to represent one memory address, which was suitable for the diagrams. Additionally, an int takes 4 bytes – which allowed 2 similarly sized slots to represent both an address and an int value.
Q: In the last movie, I can see the value “5” contained within just one byte (when switching the view to 1-byte at 1:13). How come then it occupies one full slot in your videos’ stack/heap (both marked as 4-bytes wide) ?
A: Regardless how small your value is, an int will always take 4 bytes. This would be the case whether the assembly was compiled for a 32-bit platform or a 64-bit one (don’t confuse with IntPtr, whose allocated size differs based on the target platform).
Q: In the reference type VS debug movie, right after the first string ("blue") is added to the ArrayList, one can see the second string ("red") in memory as well (at 1:24). How come ?
A: Both strings are already there because the compiler allocates them beforehand. However in the code, the ArrayList only uses a reference to the first string; it does not yet know about the second. A balance had to be found between showing things as they really are in memory, and keeping the diagram clear enough so that it promotes understanding. I thought about adding both strings from the very start, but felt it raised more questions that it finally answered.
Q: What if the method I’m calling has an overload for my specific value type, but internally it’s doing boxing against the value instance?
A: If you have no control/visibility over that method, then this is as far as you can go. You’ve done your best in avoiding the boxing operation from your own code. If the method in question belongs to the FCL (Framework Class Library), then most likely you’ll be able to find its source code here. The FCL is mostly written in C# (source of this statement here and here), and provided you take the time to study the code you’re calling, you can determine if boxing does indeed occur; if there’s no boxing, all is well, and if there is, decide whether you can live with the performance impact or find a different way of achieving your goal.
Q: There are 3 types of addresses within the stack in the pictures presented. What do those represent ?
A: As per Windows Internals:
When a thread is created, the memory manager automatically reserves a predetermined amount of virtual memory, which by default is 1 MB. […]Although 1 MB is reserved, only the first page of the stack will be committed […] along with a guard page. When a thread’s stack grows large enough to touch the guard page, an exception occurs, causing an attempt to allocate another guard. Through this mechanism, a user stack doesn’t immediately consume all 1 MB of committed memory but instead grows with demand.
Pavel Yosifovich et al. – “Windows Internals”
So one ends up with 3 regions – committed pages (that contain data in use), guard page(s) and reserved pages. Note that there doesn’t need to be one single guard page, there can be multiple ones one after the other (one of the authors of Windows Internals, Alex Ionescu, was kind enough to confirm this). You can actually see on the VMMap screen captures that more than 1 guard page is present. If you want to read more about the whole concept of guard pages, look at this, this and this. And also take a look at the _chkstk function belonging to the C/C++ runtime.
Q: But there’s a category “Heap” and “Managed Heap” in your VMMap snapshots. What’s up with that ?
A: The “Managed Heap” is what the .NET runtime uses and presents to a .NET application. As per VMMap’s help file: “Managed heap represents private memory that’s allocated and used by the .NET garbage collector“. The other category – the “Heap” – contains “Application memory allocations using the C runtime malloc library, HeapAlloc and LocalAlloc“. Though the .NET runtime internally uses the heap to build its own managed heap, of interest to us is only the “Managed Heap” category.
Q: Are type object pointers absolute, or their value changes from run to run ?
A: The type object pointers are simply the location of the method table in memory. They’re not guaranteed to stay unique, of course, from one run of the same code to another. After all the method table gets assigned in memory at a virtual address that get dynamically assigned in the process’s address space, as the Windows implementation of the CLR sees fit.
Q: You mentioned the sync block index for a reference type object. Where is this stored ?
A: This is stored in the heap, ahead of the object instance by either 4 bytes (if the code is 32-bit) or 8 bytes (if the code is 64-bit). There’s an article on the Wayback Machine here which goes really low level with both the sync block index and the type object pointers.
Q: Why is the “blue” string displayed in the memory window with the letters in the wrong order ? Eg the last DWORD is shown as 00 6c 00 62 while the portion of the string is b.l..
A: This is due to endianness. The “Memory” window in Visual Studio’s debugger by default has 3 parts – the addresses on the left, interpreted data in the middle, and a text equivalent to the right. Now, a memory address will contain exactly 1 byte. The text area – provided you have the default “ANSI Text” option selected – will convert each byte to its ASCII representation. Therefore what you see in the text area is the reflection of the real order of data in memory. However the middle section, which displays interpreted data, will default to “4-byte Integer”, or a DWORD. When interpreting a sequence of more than one byte, one must be aware of the endianness used to represent them. Take an example: if at a memory address you find, in order, the 4 bytes 12 45 78 AB, then if you’re interpreting these as a 32-bit number (4-byte integer or DWORD) in Big Endian you’ll get 124578AB; yet if you use Little Endian, you’ll get the number AB784512. Little endian simply treats the least significant byte in the sequence as the most significant one in the final number (and so on until all bytes have their places “reversed”). You’ll notice that once you toggle to “1-byte Integer”, the “Big Endian” option becomes greyed out – there’s no use for endianness when you’re looking at individual bytes. Coming back to the initial question, if you want to see the byte values “in order”, simply toggle on the “Big Endian” option.
Q: I don’t really trust Visual Studio’s debugger. Is there anything else that I can use to see the content of various memory locations ?
A: Yes, WinDbg. You can find an example in the next question.
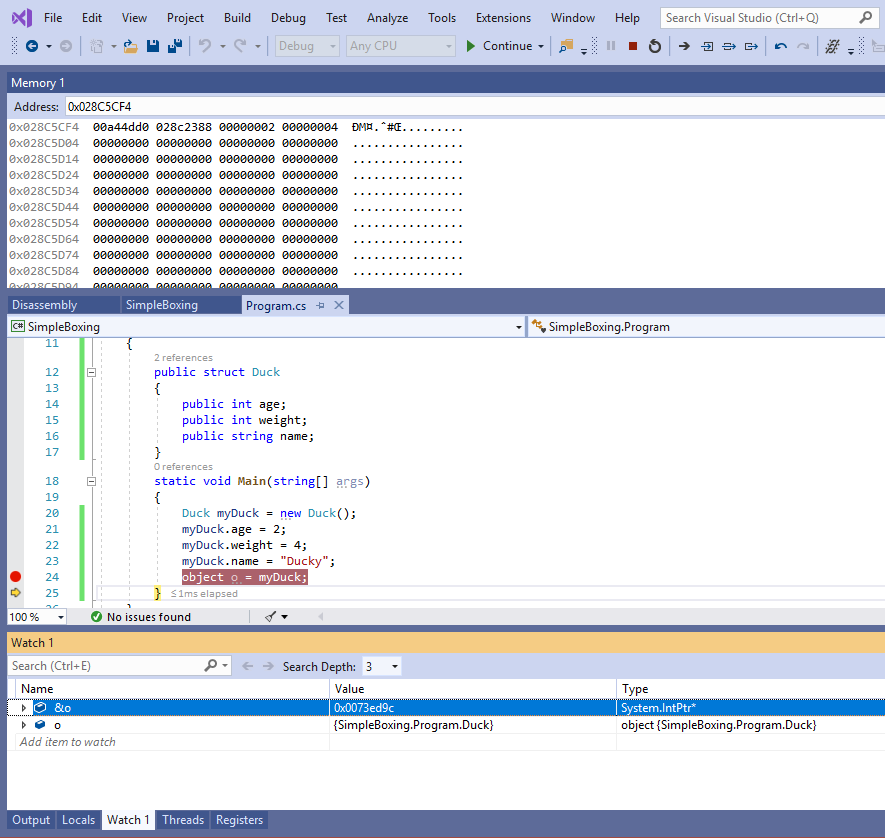
Q: If a struct contains a string field, is the raw content of that particular field belonging to an instance of the struct a reference to the string instance located on the heap ?
A: Yes, see the example below, where an instance of the Duck struct is declared as a local variable. The compiler decided to arrange the fields so that the string is first, and int is second. You can clearly see this in the output of the second dd line – the address where the string lives is first, followed by the actual value of the int field (you can also see it in the disassembled code, since the string is stored at the address within the reference type variable, and the int is placed at +4 bytes). Important: don’t trust the registers in WinDbg; despite the fact that the thread being analyzed is the correct one (the Threads window in VS can be used to check – see red highlights below, indicating process and thread), you can see that the location of the current instruction (7719a8fc for “ret 0Ch” highlighted in orange) is quite different from what the VS disassembly window shows (EIP highlighted in orange, which is the instruction pointer, matching what the left of the disassembly window is showing). The same problem can be seen with EBP (base pointer, can be used to index into the stack): querying the data at an address relative to this register shows wrong information (first green highlight to the right); however using the correct value that VS displays in the Registers window will point to the correct content of our local variable, including the reference to string. The string itself can be seen below highlighted in yellow. (For this WinDbg registers issue, I’m definitely messing up something, I just need to understand what; I’ll update once this happens).
Q: Which one is better, the heap or the stack ? When should I use one versus the other ?
A: Well, it’s kinda like asking which is best, a fishing rod or a remote control. Each does a specific thing well in a certain context, and thus you’ll want to use each accordingly. Each has its own advantages and disadvantages. For heap:
- GC (Garbage Collector) will run against it periodically, purging objects that are no longer in use. This translates in a performance hit when the GC runs
- Copying is fast, since only a reference needs to be copied
- Usually large, can be used to store large amounts of data
- Allocation is slower than on the stack, since there are custom structures describing the allocated and free portions of the heap that need to be updated
For stack:
- no reference needs to be followed, and information can be accessed within the stack just by indexing into EBP (Extended Base Pointer, a CPU register)
- limited to a rather small value by default (1 MB)
- lighter implementations than objects – there’s no type object pointer or sync block index to consider and keep updated
- allocation is fast, since it only involves modifying EBP and a contiguous block of memory
- no need for a GC, since it’s managed automatically (variables are automatically destroyed (and removed from the stack) when out of scope)
For more information, you can start with this, this and this SO threads.
Q: What happens if you use a reference type variable that has only been declared, but not initialized ?
A: If one only defines a reference type variable, the variable will be made to contain null. Used as such – in this non-initialized state – a NullReferenceException gets thrown. The outcome is quite normal, as one cannot simply go to address null in memory.
Q: What other uses of the stack are there, aside from storing certain local variables ?
A: This is a long discussion; a starting point is here.
Q: So when I build my simple C# app, then run that code, how many stacks and heaps will my process have ?
A: In the Windows world, by default, you’ll get one heap overall and one stack for each thread your application creates. Hence the whole discussion about “the stack” is a bit wrong, since by default there can be multiple of them. Eric Lippert actually touches on this in his answer here. If you’re building for the 32-bit platform, and running your code on 64-bit Windows (Wow64), the number of stacks is double (each thread gets a 32-bit one and a 64-bit one).
Q: I don’t really understand what you’re saying in this post. Where can I find information about these topics, but written by others ?
A: Eric Lippert has a series of blogposts here that deal exclusively with value/reference types/stack/heap and the myths/misinformation surrounding them; to name just a few links: here (the discussions breaks out of the usual stack vs heap and goes to talk about lifetime of data and implications it has for the underlying storage medium) and here (decoupling of the type system from the underlying storage medium). This presents Microsoft’s own intro article to boxing and unboxing. Jon Skeet has interesting articles (aside from his books, of course): for a brief explanation of value/reference types are and where they’re stored, see this, for a discussion of parameter passing in C# take a look at this; for a discussion about references, this. There are multiple StackOverflow threads that discuss the topics this article touches upon, and in quite a few of these threads knowledgeable people like Eric Lippert and Jon Skeet provide great insights, such as the one here, here or here. In general, you’ll find a wealth of information in SO threads where the words “Lippert“,”stack” and “heap” show up together.
Q: What other things can lead to boxing, aside from an implicit conversion to object ?
A: A conversion to an interface type will cause boxing as well, as Jon Skeet mentions here. Also, as per “C# in Depth (3rd edition)“: “boxing will always occur when you call GetType() on a value type variable, because it can’t be overridden“. There are quite a few other ways, discussed here.
Q: How can I see methods that take an object parameter within a specific assembly ?
A: There’s a previous post about this on this very site here.
Q: What changes when compiling for 64-bit, instead of 32-bit ?
A: The addresses themselves become 64-bit. Take a look at how the Visual Studio debugger’s output changes when the boxing sample seen in the last movie is recompiled for 64-bit:

Q: The samples in this post only show boxing for an int. But how about a user-defined struct, does that get boxed ?
A: As long as it’s a value type, it can get boxed. Consider the code below. In the “Memory 1” window you can see the boxed result of the struct instance, stored on the heap. In order, there’s the type object pointer, the address of the string object that contains “Ducky”, the age and the weight.