Last time we saw that the code that added random numbers to the ArrayList instance was spending 75% of its total time (1,141.5 ms) just doing GC. Computing the other 25%, representing the actual work, gives out about 285 ms. But how can this be, since the time the List<T> code takes – including its own GC activity – is 223 ms? Is the List<T> implementation really that much efficient, that even with GC activity, it manages to complete faster that the actual time spent doing work in the case of the ArrayList one? Are generics just that magical?
In this post – the last of a 3-part series (part 1 here, part 2 here) – we’ll go over the notion of generics, look at the sample code we’ll use, analyze the implementation behind the List<int> type, discuss expected and actual Garbage Collection outcomes, compute the effective work run times using 2 different methods, look at the memory usage and finish with the overall conclusions, followed by a set of Q&A.
Just as specified in the previous post, please note that the discussion will be around the .NET Framework for Windows. All the code discussed is 32-bit (x86), although the concepts are applicable to x64 as well. Also all the benchmarked code is compiled in “Release” mode. In terms of GC, we’re specifically looking at Concurrent Workstation GC, not Server GC.
Sample Code
The one below is the “sample code” that we’ll use as the start of our analysis and to which we’ll refer throughout the article. It does the same exact job for which ArrayList was employed previously – adding 10 mil random int values to the same collection:
const int noNumbers = 10000000;
List<int> numbers = new List<int>();
Random random = new Random(1); // use the same seed as to make
// benchmarking consistent
for (int i = 0; i < noNumbers; i++)
{
int currentNumber = random.Next(10); // generate a non-negative
// random number less than 10
numbers.Add(currentNumber); // NO BOXING
}
Just as in the last article, let’s identify and highlight each operation within the loop:

As opposed to the ArrayList code in the previous post, this time there’s one less instruction within the loop: the one that did the boxing (object o = currentNumber). Yet unlike passing the int value directly to ArrayList‘s Add method – which does not bypasses the boxing – in the List<int> code sample here there’s no boxing occurring at all. Why? Because List<int>‘s Add method actually takes an int parameter. Take a look at the Visual Studio’s relevant Intellisense entry:

But does what this List<int> stand for, after all?
Generics, Concretely
What are generics? They’re a feature of C# that allows code reuse, by allowing a common algorithm to be implemented using multiple types, all while avoiding writing identical pieces of code for each type. In our specific example, List<T> is the generic type, and in our sample code we’re only using the int-based implementation. The int type is called the type argument in this case.
What does the compiler do when it encounters our generic type the first time? How will the native code look?
When a method that uses generic type parameters is JIT-compiled, the CLR takes the method’s IL, substitutes the specified type arguments, and then creates native code that is specific to that method operating on the specified data types. This is exactly what you want and is one of the main features of generics.
Jeffrey Richter. CLR via C#
So for our sample code we expect the equivalent native code’s methods – eg Add – to be working with int objects exclusively, and have their inner machine code only deal with int objects as well. This in turn has the following important implication:
Because a generic algorithm can now be created to work with a specific value type, the instances of the value type can be passed by value, and the CLR no longer has to do any boxing.
Jeffrey Richter. CLR via C#
But let’s look first at the source code for List<T>, to understand how it works under the hood, even before it gets to the point of being compiled.
List<T>
The great thing about List<T>, as well as ArrayList and all the types included in the BCL (Base Class Library) is that their source code is available in the Reference Source.
The source code for the List<T> class is present in the Reference Source, here. Of interest to us are:
- The fields belonging to
List<T>(lines 38-47):
private const int _defaultCapacity = 4;
private T[] _items;
[ContractPublicPropertyName("Count")]
private int _size;
private int _version;
[NonSerialized]
private Object _syncRoot;
static readonly T[] _emptyArray = new T[0];
- The parameterless constructor (lines 49-54); the comment specifies the initial capacity as 16, but the code above clearly shows it’s 4 in reality
// Constructs a List. The list is initially empty and has a capacity
// of zero. Upon adding the first element to the list the capacity is
// increased to 16, and then increased in multiples of two as required.
public List() {
_items = _emptyArray;
}
Addmethod (lines 216-224), which adds the supplied value at the end of the_itemsTarray and increases the version/size of theList<T>. This depends on…
// Adds the given object to the end of this list. The size of the list is
// increased by one. If required, the capacity of the list is doubled
// before adding the new element.
//
public void Add(T item) {
if (_size == _items.Length) EnsureCapacity(_size + 1);
_items[_size++] = item;
_version++;
}
…EnsureCapacity method (lines 401-414), that ensures a large enough capacity value is chosen based on the input parameter. This in turn depends on…
// Ensures that the capacity of this list is at least the given minimum
// value. If the currect capacity of the list is less than min, the
// capacity is increased to twice the current capacity or to min,
// whichever is larger.
private void EnsureCapacity(int min) {
if (_items.Length < min) {
int newCapacity = _items.Length == 0? _defaultCapacity : _items.Length * 2;
// Allow the list to grow to maximum possible capacity (~2G elements) before encountering overflow.
// Note that this check works even when _items.Length overflowed thanks to the (uint) cast
if ((uint)newCapacity > Array.MaxArrayLength) newCapacity = Array.MaxArrayLength;
if (newCapacity < min) newCapacity = min;
Capacity = newCapacity;
}
}
…Setter for the Capacity property (lines 121-132), which when used – and provided the value supplied as capacity is larger than the length of _items – allocates a new large enough internal array and copies across the old elements. Only the part of interest from the setter is shown below:
if (value != _items.Length) {
if (value > 0) {
T[] newItems = new T[value];
if (_size > 0) {
Array.Copy(_items, 0, newItems, 0, _size);
}
_items = newItems;
}
else {
_items = _emptyArray;
}
}
Notice that the code is virtually identical to the one we’ve looked over for ArrayList in the previous article, even down to some of the typos in the comments. The only significant difference is that now the internal array is of type T[].
A couple of words about the fields and constants belonging to the type, that we’ll keep an eye on. The type of each is within brackets:
_items(T[]) represent the actual items being stored in theList<T>_size(int) contain the number of elements currently within theList<T>_version(int), for what we’re interested it simply contains a number that gets incremented with each element addition. Thus it will always be equal in our case with the value within_size_syncRoot(Object) – not of interest for us_defaultCapacity(const int)emptyArray(static readonly T[]) – contains an empty array (with elements of typeT)
So how exactly do we go from this generic T type to our int? After all, in our code we’re after adding numbers that are ints, so the Add method is supposed to process these, not T elements. Recall the quote from earlier:
When a method that uses generic type parameters is JIT-compiled, the CLR takes the method’s IL, substitutes the specified type arguments, and then creates native code that is specific to that method operating on the specified data types.
Richter, Jeffrey. CLR via C#
Based on the quote above we’ll replace T with int, and through the analysis of the List<T> inner code and accompanying comments, this is what we’d expect to see happening when running our sample program:
- When the
List<int>is initialised, the internal_itemsvariable will contain a reference to an emptyint[]array - Once the first element is added to the
List<int>,_itemswill contain a new reference, that points to a newint[]array of length 4 (_defaultCapacityof the_itemsarray). The first number is simply copied as the first element in this array - For each subsequent
int, its value is placed in the same array as the next element - When the fifth element is added to the
ArrayList, again_itemswill contain a new reference, that points to yet anotherT[]of double the previous length. This new double array will contain all previously added elements - The process continues similarly until all the numbers are added
Let’s see next how each number generated gets added to our List<int> instance, as part of the sample code, and particularly what goes on inside the List<int> structure as this unfolds. A few things to keep in mind:
- The format is the same as in previous movies: the debugging against the code in Visual Studio happens on the left, while a conceptual diagram showing what goes on gets updated accordingly on the right
- The same known random sequence of numbers is used, so comparing against the
ArrayListmovie in the previous post is straight-forward - We’ll only look at the first 6 numbers
- You’ll notice a few entries marked as
<top>. Those represent type object pointers, which were discussed in the first article of this series. Their values (hex addresses) weren’t added in order to avoid complicating the diagram. Also – just because<top>was used everywhere doesn’t mean that the address is the same everywhere. In each case it represents a type object pointer, not the type object pointer - The diagram will not capture the length of the
List<int>itself, which grows by 1 as each number gets added, but focuses only on the internal_itemsarray and its size - The following color codes are used for the highlights within the memory windows: violet (type object pointers), red (reference addresses), green (values, such as array sizes, array value elements, etc)
- The variables of interest – the current number generated and the
List<int>instance – will be pinned (pinned data tips) in the UI so the value of the current number and the number of elements added so far to the list are visible
Garbage Day
What would we expect to see from a GC standpoint? To answer this, we’ll have to think of what actually gets allocated on the heap – which, remember, is where the GC operates. Also what goes on SOH and LOH will be important. The length of the internal arrays starts from 4 and doubles at each step, exactly as for ArrayList. Each element of these internal arrays still takes 4 bytes – that’s the space occupied by an int (regardless of platform, be it x86 or x64), identical to how much an object took on the x86 platform against which the ArrayList code was compiled (recall back then object[] internal arrays were used).
As seen in the movie, there’s no more tons of individual boxed ints floating around. Instead, we’re just dealing with regular int[] arrays. And since their length grows pretty fast by doubling at each step, there will only be a few that land in the SOH, given that they have a total length of less than 85,000 bytes (equivalent to an array with ~20k elements). As soon as this value is exceeded, the rest of the int arrays – which will occupy the bulk of the memory used by our sample code – will go over in LOH.
Definitely not much gen0 or gen1 GC would be expected, since we’ll mostly add only to the LOH. And there’s only one type of GC that operates on LOH: the gen2 GC. So if anything – we’ll expect to see mostly gen2 GCs occurring.
Actual GC Activity
Let’s look at what actually happens in terms of garbage collection. We’ll employ BDN against our sample code (source here), and set an unrollFactor of 1, so that only one operation – itself consisting of adding 10 mil int values to a List<int> – is run per iteration. We go this way, as opposed to leaving the default number of iterations BDN chooses for this sample code (3) as to avoid summing up all the GC time per iteration and then dividing by the number of ops/iteration, as it was done in the previous article. PerfView will be run in parallel, with “GC Collect” set as capture option.
Remember that BDN manually induces a set of GCs between iterations, so pinpointing GC activity originating directly from our own code is pretty simple to identify – just look at the block of lines that don’t have Induced as the trigger reason within PerfView’s GCStats output. Note below the GCStats view for the last iterations:
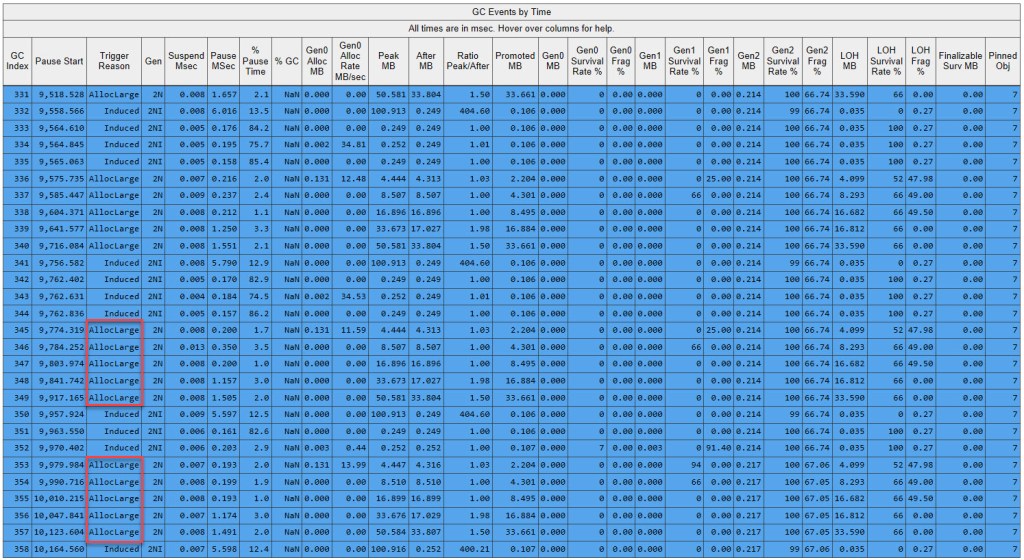
Just as expected, all the GCs triggered by our code are gen2 (note the designation 2N), and the reason is AllocLarge. Recall (as discussed in “GC, Revisited” previously) that AllocLarge means that the large object threshold has been exceeded.
In the GCStats Condemned Reasons table, we can see the gen2 budget exceeded – due to LOH growing – every single time a GC runs:
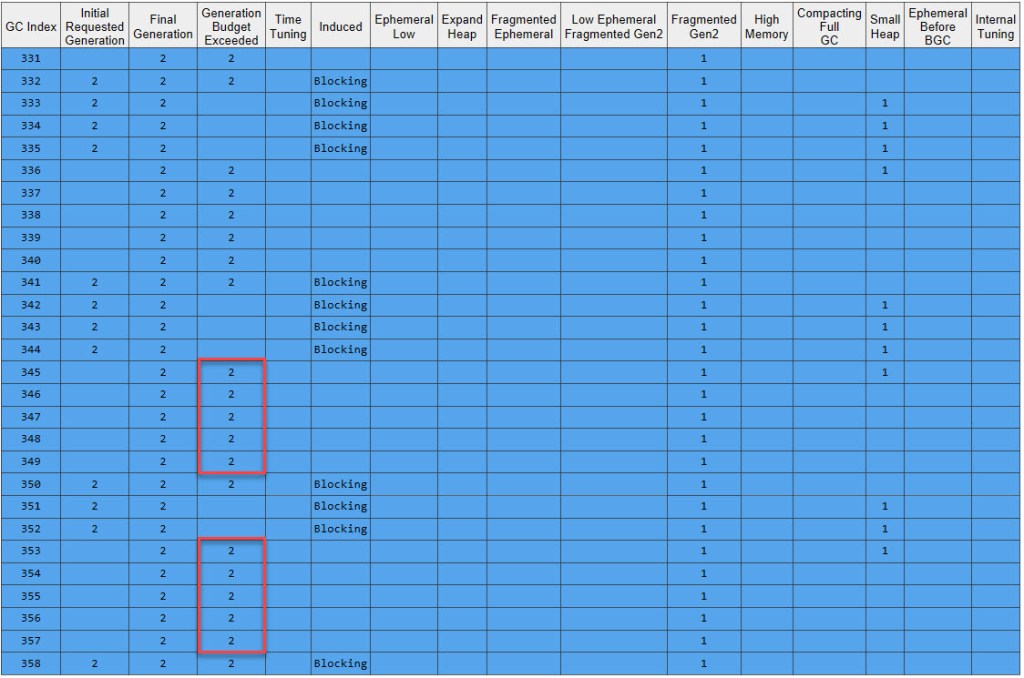
We can see that the final generation chosen by the GC is always 2.*
Why aren’t there any individual gen0/1 GCs? After all, there are some initial internal arrays (of length 4, 8, 16, 32, 64,…) that will get placed on the SOH. Don’t this get reclaimed by the GC? The thing is that as long as there’s no trigger – say generation budget exceeded or another one – there won’t be any GC running. And in our case, those arrays barely make up a few KB, so there’s no generation budget exceeded, as we saw plenty of when dealing with the ArrayList sample code. If the CLR doesn’t consider a GC to bring advantages, then it won’t waste time (and decrease performance of the user code running) by invoking it. But eventually a gen2 GC runs and collects those arrays – remember that a gen2 GC will do both collection of gen0 as well as gen1 – and one can be clearly see in the “Gen0 Alloc MB” column for the very first GC of each iteration that occurs during our code how much memory was allocated in gen0 (from the last GC that occurred, which was the last induced one by BDN). This value drops to 0 in the iteration’s subsequent GCs, as the internal arrays are already large enough and will be allocated on the LOH instead. Also note that “Gen0 Survival Rate %” is always 0 during the GCs ran as a result of the user code: despite allocating those small internal arrays in gen0, they don’t need to be kept around and stored in gen1 as newer, bigger arrays come along that make these small ones obsolete and unneeded.
Next, let’s measure the time spent doing actual work by the List<int> sample. We’ll employ 2 different methods, similar to how it was done in the past article.
Time Measurement (Onion Approach)
So what’s the total time spent doing effective work? We’ll obtain this by subtracting the GC time from the total time the code spends running. Similar to how to the outer layers of an onion are peeled off, we’ll do the same with the GC time in order to get to the “core” – the time spent doing actual work in adding elements to the List<int> instance. Based on the BDN code described previously, let’s see the raw output:
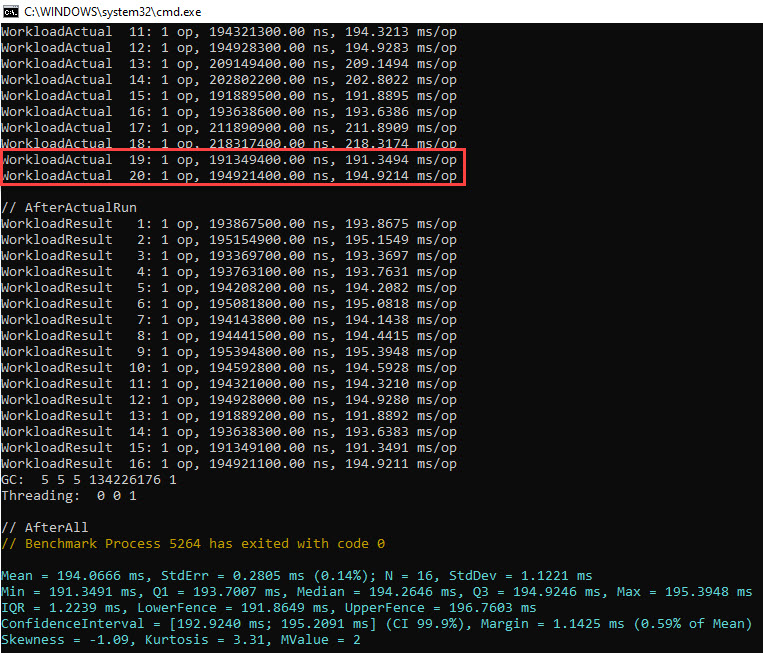
The last 2 iterations are highlighted, and we’ll use these 2 to sum up the GC times per each. Why are there only 16 measurements in the //AfterActualRun, when the previous section contains 20? It’s because the outliers – such as iterations 17 and 18 – are removed automatically by BDN (just as it was described in this section in the previous article). And why use the last 2 iterations? Just so we can scroll to the end to the Excel file that PerfView exports, and quickly sum up the GC times:
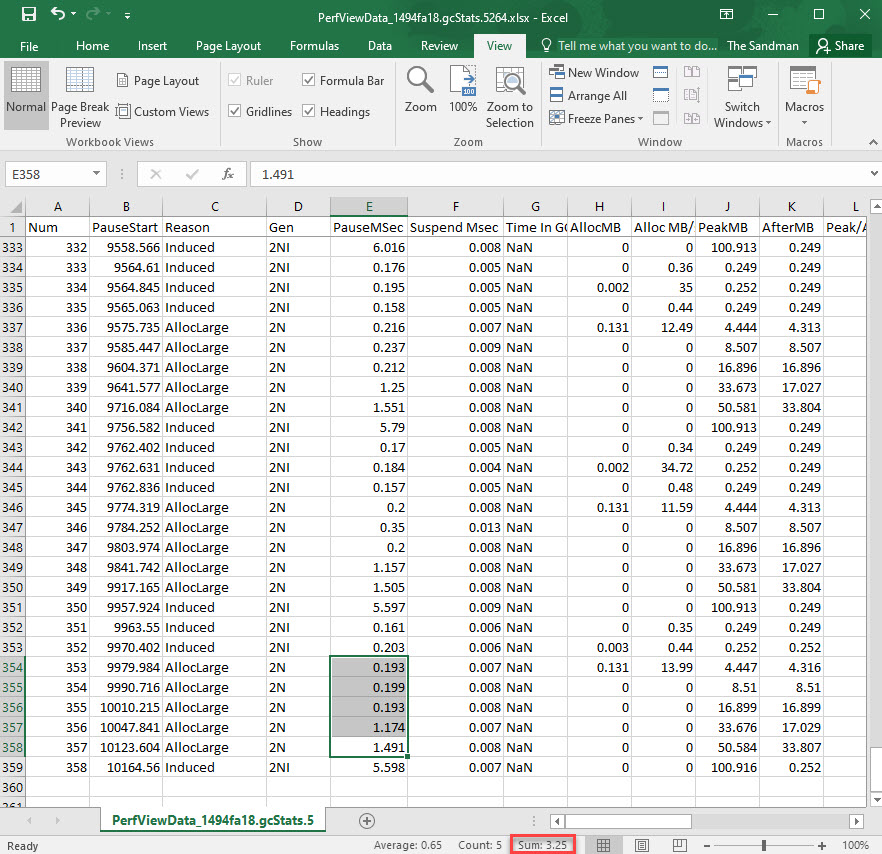
Now we can sum up the individual GC times for the last iteration – which gives out 3.25 ms spent doing GC. The rest up to 194.92 ms is effective work; in other words the GC accounts for just 1.7% of the time it takes for 10 mil int values to be added to a List<int> instance.
Looking at the penultimate iteration, the GC percentage is still the same at 1.7% (3.41 ms out of 191.34 ms).
Note that there’s no background GC occurring (as in 2B), so there’s no need to look at the time “stolen” by background GC activity on its dedicated thread. Since all 5 gen2 GCs triggered by the user code are 2N (non-concurrent), the time shown by GCStats is all the main managed thread has to ‘pay’ in terms of time.*
But how can this be? How can GC in the case of our List<int> sample code take 1.7% of the total run time, versus a whooping 75% it takes out of the ArrayList‘s sample code run time? Isn’t there some mistake?
Let’s double check by computing the effective time in a different way.
Time Measurement (Replicator Approach)
The second way to go about measuring how long things take is to replicate the operations that the List<int> code performs, and time them in isolation: the loop, generating each random number, and adding each element to the List<int> instance. For the latter, we’ll even go deeper with the aid of the BCL source code (stored in Reference Source). The advantage is that we get to see how the time is spent internally, as opposed to the previous method which just yielded the total time doing effective work as an opaque value.
Based on the fact that a small platform change (as in .NET version) for the machine used to run the tests resulted in slight time improvements (as seen in this question previously), before starting, let’s run the benchmark with both ArrayList and List<int> again, to ensure the overall numbers still hold (code here):
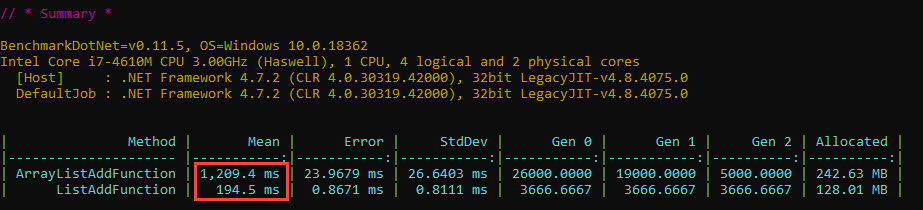
This is pretty close to our original results seen in the first picture of the first article in this series, so let’s continue.
Due to the same platform change mentioned above, we’ll also redo the individual tests for operations that are common between the List<int> and ArrayList sample codes – namely the loops (optimized and non-optimized) and generating the random numbers:
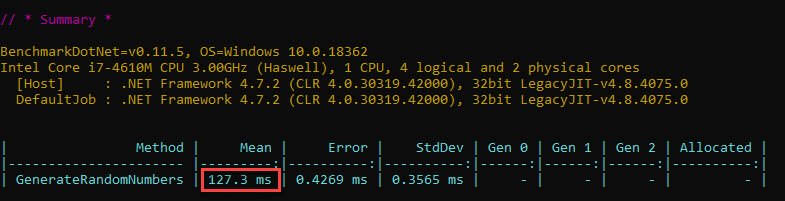
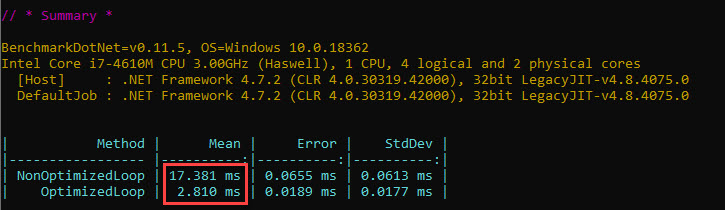
The numbers are quite close to what we’ve seen in the previous article, so let’s move on.
How about the remaining step of our sample code – adding the element 10 mil times? We’ll time how long it takes to just add the same (value) element to our List<int> instance 10 mil times. Since we have the source code of List<int>‘s Add method – along with the inner methods – we can also replicate its behavior by splitting it up into the essential tasks going on within each Add.
As we’ve seen when we’ve went over the Reference Source code for List<T>‘s Add, things resemble very well the code for ArrayList‘s own Add. In a nutshell, the elements are stored as pure values in internal int[] arrays – starting from a length of 4 -, and get populated incrementally with each new subsequent element. Once one array is filled, a new one – double the size of the current one – gets allocated, the elements carried across, and the process of adding new elements continues as before. As such, 23 internal arrays will be needed, finishing with one of length 16,777,216 (large enough to contain our 10 mil elements). Therefore the operations that should take significant time remain the same, namely:
- (a) Defining all the intermediary internal
int[]arrays within theList<int>instance. This refers to allocating the memory for the respective structures - (b) Copying the elements from the internal
int[]arrays to the new ones that are double in length, when the former are no longer large enough to keep the current number of elements - (c) Adding one element at a time to the
List<int>‘s internalint[]array. Since we’re looking specifically only at the performance of the inner code involvingList<int>, we’d want to add the same precomputedintelement, as opposed to generating a random number and then adding it, which was already studied and timed separately before
We’ll use the same tricks we’ve employed previously to keep the GC at bay section: pre-increase the allocation budgets* and use 1 op/iteration in BDN.
We’ll create 6 methods, as follows:
- The first method defines a
List<int>instance large enough for our 10 mil elements up front, using a specific constructor - The 2nd method corresponds to (a) defined previously. It creates
int[]arrays – each double the length of the previous one – up until the one of length 16,777,216 - The 3rd method corresponds to (b) defined previously, and uses regular
int[]arrays. Copying elements to the last internalint[]array is done only for the first 10 mil however – as opposed to the full length of 16,777,216 – in order to mimic what happens from this standpoint withinList<int>‘sAddmethod in the sample code - The 4th method does (a)+(b)+(c), and it’s implemented using regular
int[]arrays - The 5th method is in terms of workload similar to the previous one, doing (a)+(b)+(c), it’s only that it uses
List<int>instance’sAddmethod - The 6th method is a combination of 4 and 5 above, as such: unlike 2 – 4 above, where everything happens within the respective methods without any call whatsoever to other methods (minus
Array.Copy), this one invokes a separate method that copies a pre-computedintvalue to each subsequent element of the currentint[]array. This replicates what our sample source code does, in the sense that a method gets called for every value that gets added to our collection of elements.
The code is here, and the results below:
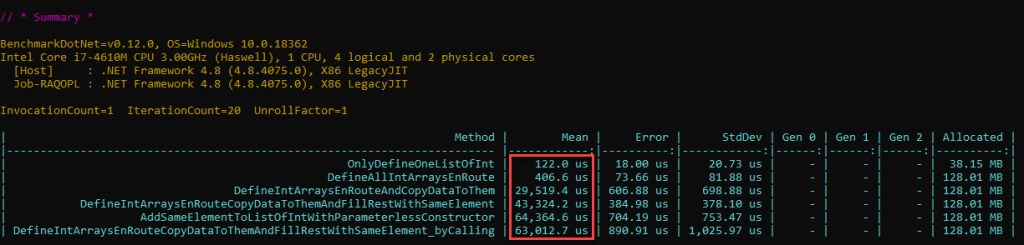
Note that the second method – DefineAllIntArraysEnRoute – has been updated so that it contains int[] arrays redefinitions, instead of List<int> redefinitions (the previous article did ArrayList redefinitions), as this is the real operation done in subsequent methods.
A quick discussion of the numbers: the time it takes for new values to be added to the internal arrays after copying the former data will be of course larger – although not really double – the time it takes to copy the data from the former internal array. At first glance, the time it takes for the code involving the “real” List<int> Add method (5th method) is expected to be only slightly larger than the copy-and-fill-elements method (4th method), since there’s an extra _version++ that gets executed per each element added, as seen in the movie. Yet the time observed (+20 ms) is significantly larger. This is explained by the repeated (10 mil times) call to the Add method – which incurs a time penalty since the stack context needs to be saved/restored each time before/after the method runs. We can replicate this behavior by employing the 6th method; note that the times for 5 and 6 are almost the same, essentially ending our search for any missing bits of functionality in List<int>‘s Add method that weren’t considered yet in our recreated methods.
Therefore the time it takes for all the 10 mil int values to be added to the List<int> instance is 64 – 3 ~= 61 ms. Note that the disassembly for the 5th method (shown in figure 12 further down) shows that a registry is used to store the iterator variable, so we know which loop time we need to subtract (optimized).
To conclude, we have the following:
- Loop (optimized): 3 ms
- Generating all 10 mil random numbers: 127 ms
- Adding an element 10 mil times to a
List<int>: 64 ms
Summing up, we end up with 194 ms – estimated time for performing the effective work of adding 10 mil random numbers to an ArrayList, not including any GC time.
Taking into account variability of the run times between iterations, this does match with the result obtained via the other method, whereby the GC time was subtracted from the overall run time, yielding an approximate time of 190 ms for the effective time when actual work is performed (as opposed to GC time).
Assembly Code Lego
We’ve looked at how each component adds up to the whole sample code, and particularly how the time associated to each component makes up the overall effective time for the sample code. Yet we need to make sure we’re not running into issues. For example, take the C# code which we’ve just went over in the last section – specifically the part that adds the same element to the List<int> instance. If the machine code that the JIT compiles to is significantly more efficient than the equivalent part in the sample code that adds each random number to the List<int> instance (say because that same element is magically cached, or a registry is used for that value while in the sample code a stack one is used) then we have a problem: we time our expected action (adding the same precomputed element) and see a time of t1, but in reality the part of the sample code that adds the value that was generated as a random number previously is a larger, t2. It follows that our estimation of the total time would be wrong, and we’ll end up providing an estimate that is lower than the real run time for the sample code. In turn we’d wrongly conclude that the GC takes more time than it really does.
It’s like checking Google Maps for the time it takes to get to your favorite restaurant across town at noon, and expecting this to be the same when you’ll want to go there in the afternoon during rush hour.
How can we make sure we won’t have discrepancies between the time values? We’ll check the resulting assembly code in both cases. First, the one for the sample code that the CLR produces; the colors match those of the regions in figure 1:
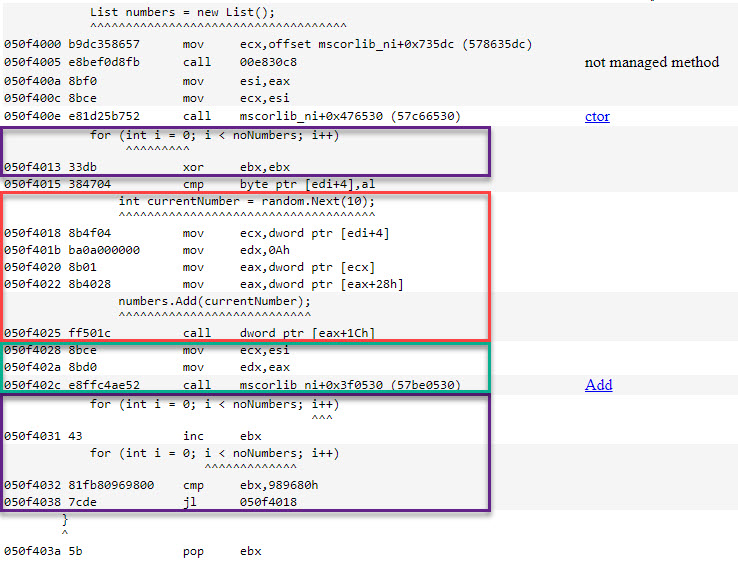
Now for the assembly code that adding the same element to a List<int> resolves to:
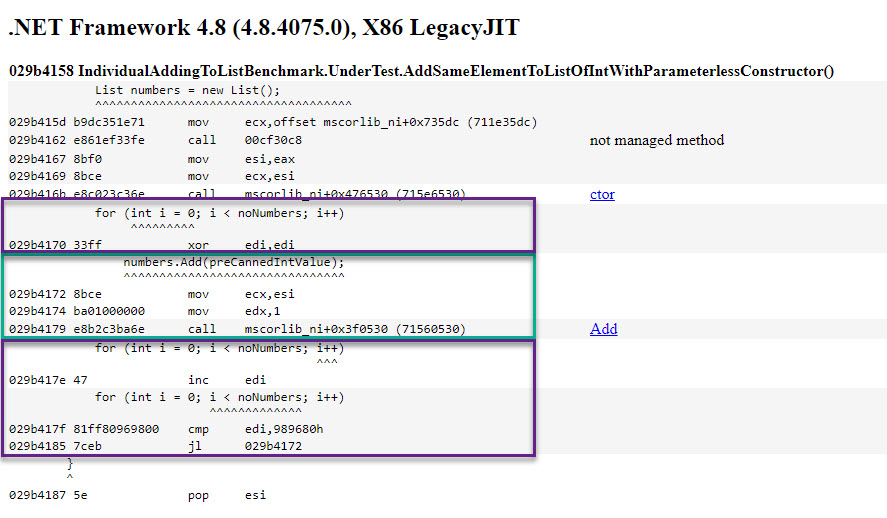
In both cases, adding the element (green highlight) consists of the same 3 assembly instructions, the only difference being the value that’s used as an input to the function called. Additionally both implementations for the loop (violet highlight) rely on registers, as opposed to stack variables. Therefore the time value for adding the same element is the same with the one it takes for the sample code to add the (already computed) random number.
Memory Usage
Before heading to the conclusions, let’s discuss about how much memory is used. We’ll have to split the discussion, as there are several values that can be measured.
In terms of memory used during the lifetime of the code, JetBrains’ dotTrace can be used to get precise data, by zooming in to get exactly one BDN iteration – itself containing just one operation (unrollFactor=1). Selecting just one iteration is easy, as the group of BDN-induced GCs always contains 4 of them, aside from the last ones (refer to figure 6). Additionally, we can see that the very first GC in that group takes significantly more. Here’s the selected timeline as such, but with the view commuted to “.NET Memory Allocations”:
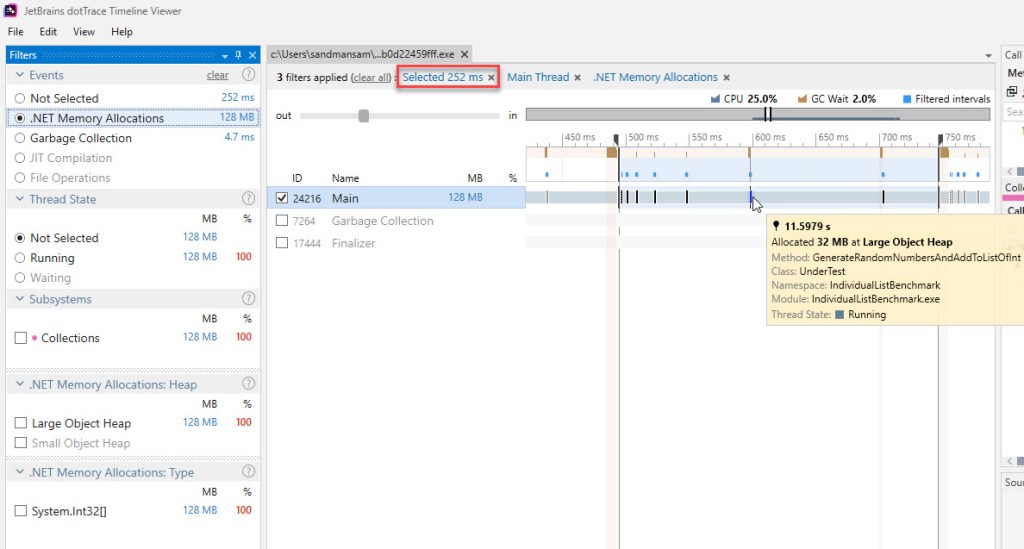
As the timeline progresses, you see allocations showing up less often, but the quantity they allocate gets larger. This is natural, as new elements are added at the same rate, while the new internal arrays double when filled.
The cursor is resting on the penultimate allocation, worth 32 MB (8,388,608 elements of the penultimate internal array x 4 bytes/element). How much is allocated for the List<int> overall can be easily computed, as the consecutive length of the internal arrays represents a mathematical series, whose sum will be (almost) equal to the double of the last length, totalling 2 x 64 MB = 128 MB.
For an ArrayList, each boxed int occupies 12 bytes, due to the type object pointer (aka method table address – 4 bytes), the value stored (an int, which takes 4 bytes on either x86/x64) and the sync block index (4 bytes). All these scattered boxed ints total 114.45 MB (12 bytes/object x 10 mil objects). On top of this we have the internal arrays themselves that get allocated in turn, and which – just like in the case of List<int> – take 128 MB (16 bytes + 32 bytes + 64 bytes + … + 32 MB + 64 MB). The total comes up to 242.45 MB.
The values above match what BDN was reporting in the previous article ( figure 2), and comes really close to what we’ve seen previously in figure 7.
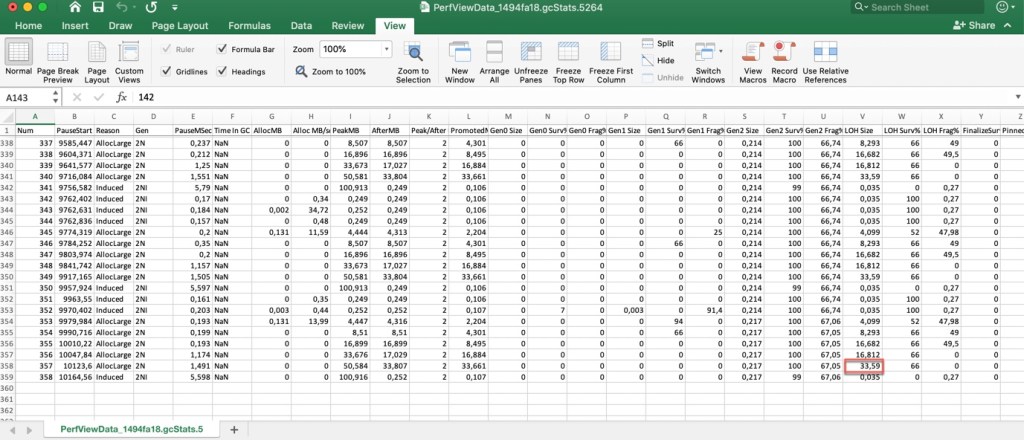
How about the memory used at a particular point in time? Even though we know that allocations occur within the LOH only, from within the GCStats view (which we took with “GC Collect” set in PerfView) we can’t quite tell how much is used at a precise time. Let’s say we want to know the quantity of memory used right after the last element has been added to the List<int> instance. We can’t quite get to our goal, because the GC is triggered by the runtime at specific thresholds, and we don’t get to “choose” the time when this occurs. The first of the BDN-induced GCs don’t yield much info neither, since the LOH size is reported after the GC completes. Note below the last of the GCs occurring during the latest iteration, showing a value that doesn’t present much interest (red highlight):
Let’s turn instead to JetBrains’ dotMemory, which can get more of what we want. Here’s how memory usage looks like after the last element is added:
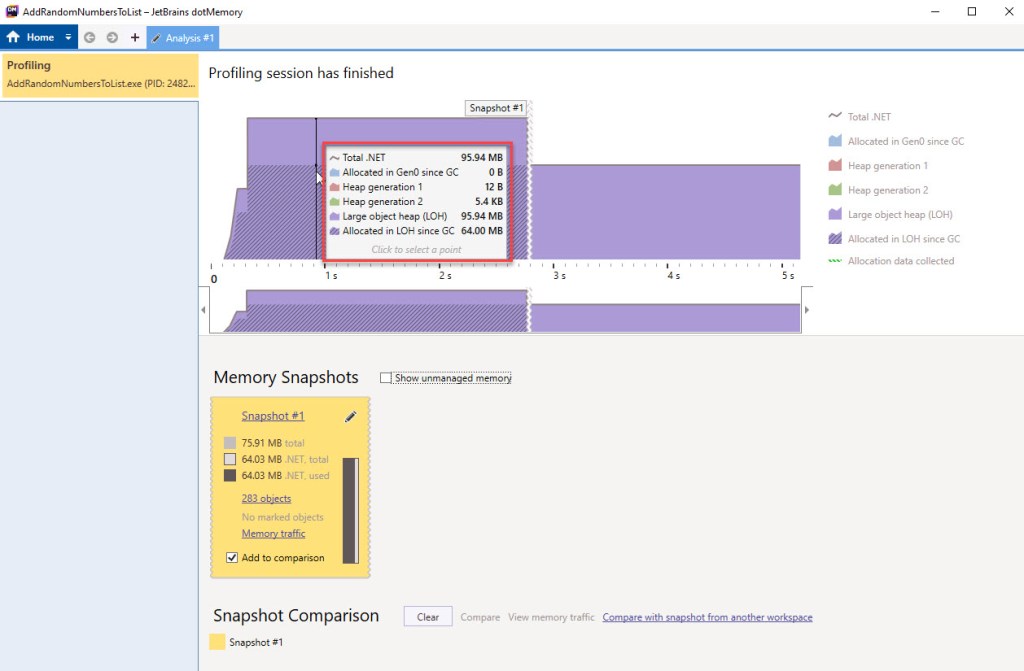
To get this output, the sample code was slightly modified in order for the code to wait for a key before exiting. Therefore you see the initial ramp up of memory, corresponding for the first 200 ms when actual activity occurs, then the usage flats out as the Console.ReadLine() is reached. 95.94 MB are in use after the last element has been added, and represents the highest memory usage for the lifetime of the sample code process.
How about the objects actually stored in the used memory? How can we see these? There’s a catch here: the objects instances can only be seen in dotMemory if a snapshot is taken; but taking a snapshot triggers a GC, which discards unused objects. Therefore, a snapshot can only show what objects are still in use, as opposed to all objects using memory right before it’s taken*. The snapshot contains the following instances:
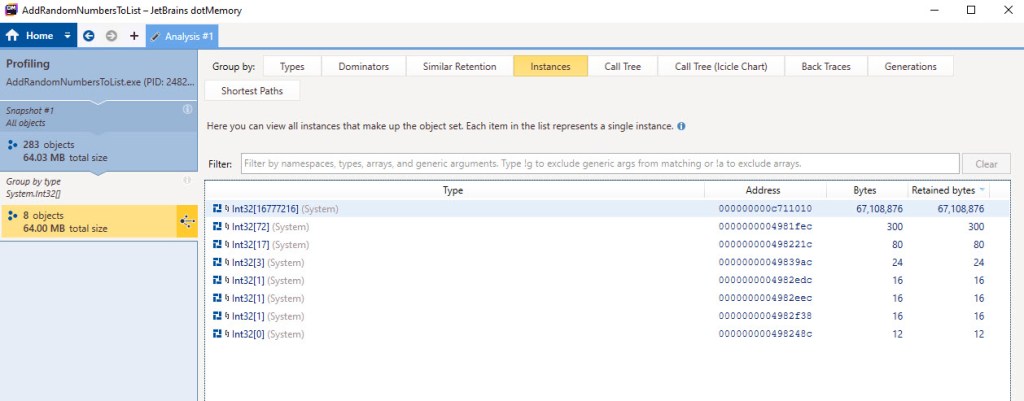
We did expect to see the internal array of length 16,777,216 here, as it’s the last allocated one and currently used to store all 10 mil int values. The rest of the internal arrays that we’ve used before – 4 bytes, 8 bytes, 16 bytes, 32 bytes, 64 bytes, etc – have been collected by GCs that already occurred . The total heap usage at this point is 64.03 MB, the majority due to the last internal array, worth 64 MB (at 4 bytes used per element).
Note that the rest of the int[] array instances in the list above are not ours, and most likely belong to the CLR, as the lengths don’t match those of our internal arrays, which are all powers of 2.
Conclusions
Since we’ve seen that the .NET Framework code is strikingly similar between List<int> and ArrayList (recollect the discussion about it right before the video), we’re coming back to the original question in this post, as to how come the effective work done by List<int> is faster than that done by ArrayList? How is this possible, given that we have the same type of doubling internal arrays used to store the elements in each case?
First, remember than adding the same (pre-boxed) element to the ArrayList instance took about 110 ms (or 92 ms on the new platform) itself, vs 60 ms for List<int>. Secondly, the boxing time (30 ms) disappears as List<int> doesn’t employ it. Sum this up and the value gets about the size of the observed difference. No magic here after all.
Let us summarize the differences between adding elements to the ArrayList and to List<int> respectively. We’ll use the gist of the videos that studied each in detail before, and use the picture below to help spot the differences at a glance:
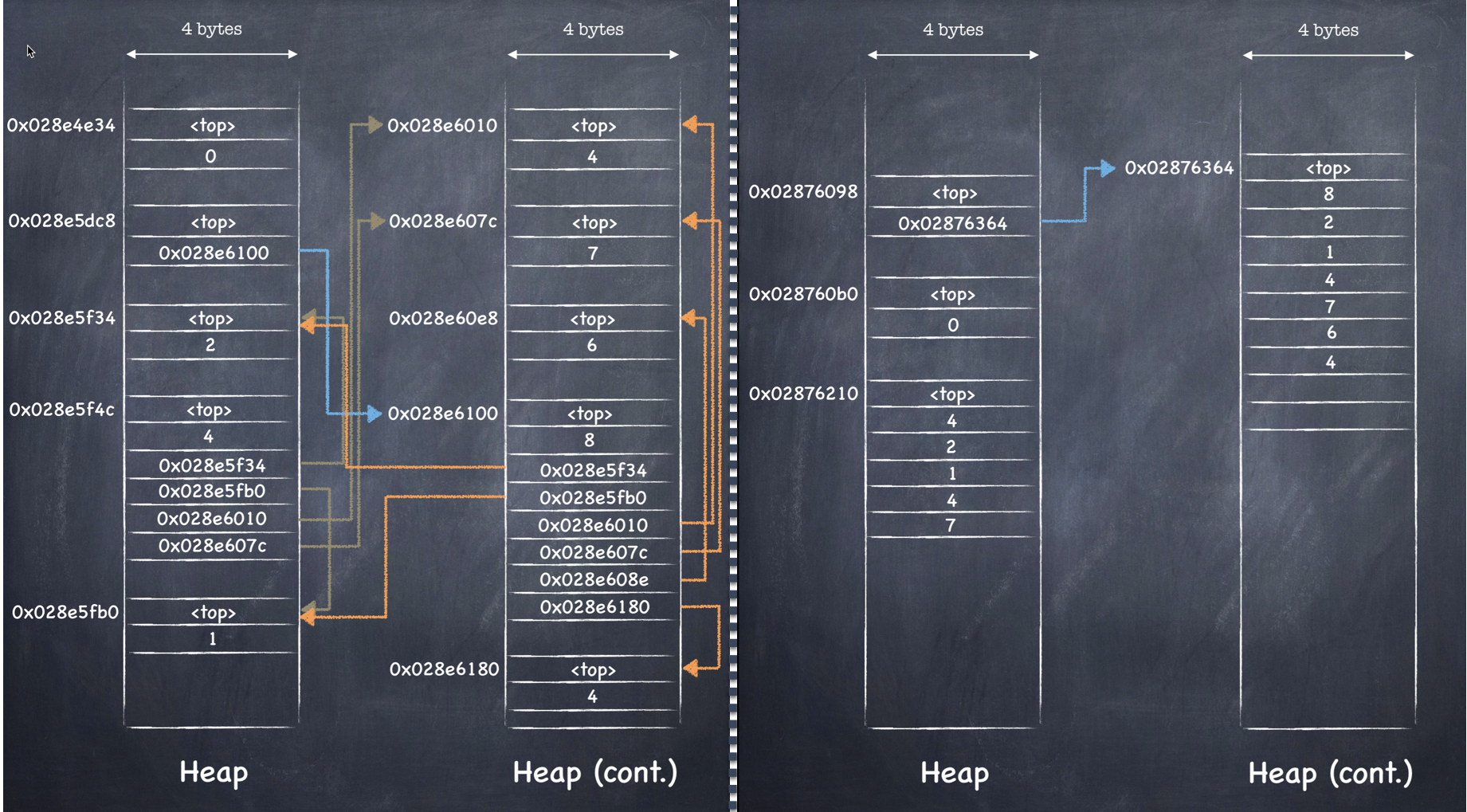
On the left side, the ArrayList‘s _items field is pointing to an internal object[] array (blue arrow), whose elements each contain individual references, that in turn point to individual objects – boxed ints – and their values (orange arrows). In contrast, on the right side the List<int>‘s _items field is pointing straight to an internal int[] array (blue arrow), that directly contains the values. On the right side, there’s a missing level of indirection, and the values themselves are stored sequentially in the internal array, which now contains the values themselves as opposed to the references.
Both ways of measuring time employed so far – (1) tracking the GC time in PerfView and (2) measuring the replicated individual constituent operations – told us that the GC time is extremely low in regards with the overall sample code time. Let’s see the relevant dotTrace output – essentially the same view as in figure 13, but scoped to “Garbage Collection”:

Notice the 2% under “GC Wait” (red highlight) – matching what we’ve seen so far, and also the fact that only gen2 GCs are running (green highlight). Remember that dotTrace does come with a performance penalty – as for this run the measured time jumped to ~240 ms – but what we’re after is the percentage of GC time from the overall run time, and this should hold.
Also note that the moments when GCs occur (figure 18) coincide with when the memory allocations are happening (figure 13), for the last major internal arrays at least. Rather normal, as GCs will occur when the LOH budget is exceeded, which happens due to the big contributors, in the form of larger arrays allocated toward the end.
The Gist
Let’s move now to the real issue and clearly state what are the reasons between the significant difference in performance between the same operations done with ArrayList vs List<int>:
- GC is by far the biggest contributor to performance difference. It’s essentially taking ages in our
ArrayListsample code case, and almost nothing in theList<int>one - Boxing itself is not the direct cause of the issue, but it’s what triggers all the
intobjects to be allocated separately on the heap and scores of references to be stored towards them as part of the internalobject[]arrays within theArrayListinstance. In turn this causes the GC to spend high amounts of time tracking all these objects down, because… - The inner arrays are all contiguous (being arrays) so allocating and reclaiming them is a lot faster, than chasing individual boxed
ints around on the heap. Plus the number of individual objects is extremely low – a contiguous array is just one object, regardless if it’s 8 MB in size. - The lifetime memory usage is roughly double for the
ArrayListsample code, and involves having to initialize and access more memory as opposed to theList<int>sample code. However just looking at the overall size allocated – ~240 MB vs 128 MB – as a potential performance issue by itself is not correct, as defining large arrays was seen to take just microseconds, and reclaiming large arrays has been seen to occur instantly for GCs within theList<int>case - Allocating the structures required in memory for each case is not wildly different (~64 ms (figure 10) vs ~92 ms (result in previous article), which would raise the question “If it takes so little to allocate the objects in the first place, why does it take so long to process them further on?”. When adding a new element, the CLR doesn’t have to look at all the other existing objects before it allocates memory and links it to the current structures; but each time a GC is run, all objects (in case of a gen2 one) have to be considered and all “links” followed, objects marked accordingly and the orphan ones reclaimed
- For
ArrayList, the GCs that occur also handle promoting objects between generations (gen0->gen1, gen1->gen2), not just reclaiming, providing yet another source of time spent
Q&A
Q: I’m running the BDN sample code and looking at the resulting GCStats table, however I’m not seeing all GCs being gen2. I thought the LOH is only processed by a gen2 GC. What’s going on?
A: You’re running into a backoff mechanism that prevents running subsequent gen2 GC. This was described previously here. As it currently stands (as of Feb 2020) the fact that gen2 GCs aren’t running is a bit confusing, as the Condemned Reasons table will show a final generation of 2, but the GCStats will show a gen1 GC, However one can be almost sure that a gen2 isn’t running based on the fragmentation level that stays the same for the LOH (as only a gen2 GC gets to operate against it). This behavior in turn results in even lower waiting times due to GC – as you could see by looking at the Pause MSec time (which includes the Suspend MSec column too) and note the extremely low times there. However, work is underway in the instrumentation to get this fixed (SO answer here).
Q: If there would have been 2B entries in the GCStats view, should these have been avoided in the sum for the total GC time?
A: They would be summed up similarly, since GCStats shows the time “the amount of the time that execution in managed code is blocked because the GC needs exclusive use to the heap. For background GCs this is small” (from PerfView’s own tooltip). Tracking the time ‘stolen’ due simultaneous access to the heap or activity on the GC thread would have to be tracked separately, as was seen in the previous article.
Q: Can the pre-increased gen budget allocation be ditched within IndividualAddingToListBenchmark code without side-effects against the GCs during one iteration?
A: The source array (masterSourceArray) can be lowered from 2 x 10 mil to just 10 mil, and GC will not kick-in. However the pre-gen budget is still needed; if the respective array is removed, then just declaring the ever-increasing arrays (en-route) will cause GCs to occur. Plus, a source is needed for the methods that copy data across.
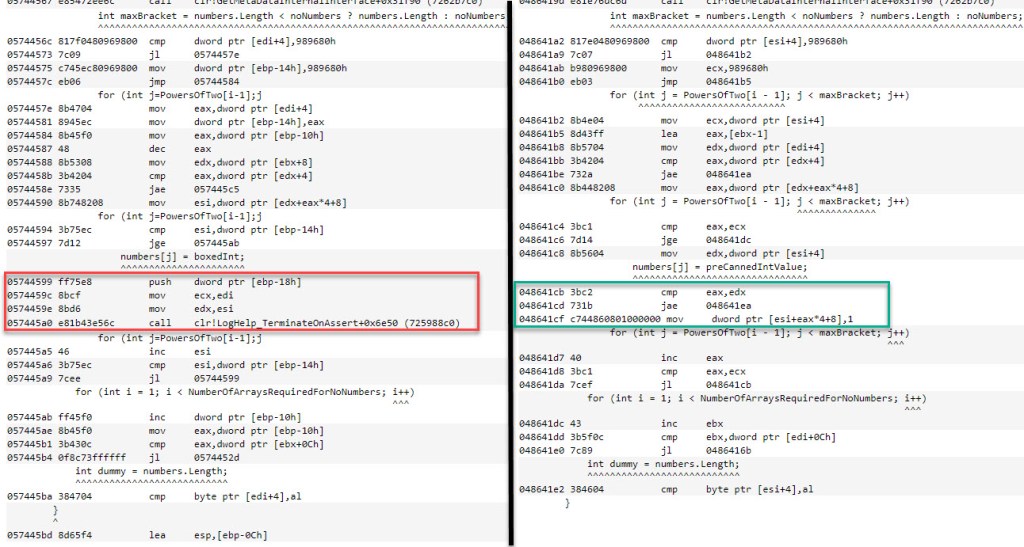
Q: There’s quite a difference between the ArrayList and List<int> run times for the method that replicates the Add method functionality.DefineObjectArraysEnRouteCopyDataToThemAndFillRestWithSameElement takes 27 ms longer than DefineIntArraysEnRouteCopyDataToThemAndFillRestWithSameElement (figure 10). Internally – aside from the object[] vs int[] arrays – everything is pretty much the same. How come the time difference then?
A: The 2 methods get compiled as seen below. Note that theArrayList‘s Add‘s replica invokes a CLR function (unresolved by BDN, only given as a relative address towards a known CLR function). Although not visible in the listing on the left, [ebp-18] is the actual pre-computed value that gets added to the internal object[] array. The trouble is that it’s stored on the stack, so every time the value is used, it gets retrieved, then pushed on top of the stack, and the function mentioned above called. This is seen in the red highlight on the left. Compare this with the code highlighted in green on the right, which achieves the same outcome for the List<int> Add‘s equivalent. There we only have a single mov that puts the known value (1) in the target address within the int[] array. Why the difference in implementations? The fact that a reference is needed in the first case probably has an implication. Last and not least, the iterator variable on the left is also stored on the stack, as opposed to the one on the right which is in a registry, thereby accounting for a few ms too.
Q: Running the BDN benchmarks for the List<int> sample code is extremely fast versus the ArrayList sample code. How come?
A: Remember that GC is the one responsible for the bulk of the time when the ArrayList code actually runs. But BDN also runs manually-induced GCs after each iteration, which themselves take time as well, since the object graph has to be traversed and the memory reclaimed, now that the execution completed (per the respective iteration). For List<int>, both GCs occurring when the user code runs, as well as the ones invoked manually by BDN take a fraction of the time.
Q: Within the List<int> Add method, aren’t EnsureCapacity and the setter called multiple times as well? Doesn’t saving and restoring the stack context take time in this case as well?
A: They are called, but only when the internal int[] array needs to be doubled. This only happens 23 times, so the overhead due to calling the 2 methods is too low to matter in our sample code.
Q: Is the 5 in figure (corresponding to figure 5) representing the average number of GCs performed per each iteration?
A: No. That represents the GC numbers for the last iteration, as we discussed previously here.
Q: I’m running BDN with the MemoryDiagnoser attribute set, but not getting any values in the attributes for allocated memory.
A: You might be running into a bug that affects .NET Framework 4.8. See this BDN issue and the update required.
Q: How about boxing? It’s said the generics avoids boxing, but how about the actual assembly implementation? Is still a mov employed as in the case of ArrayList (figure 3 here), after zeroing out the chunk of memory that gets allocated for the array? Is there any “smart” thing generics do, or we’re just seeing it perform faster because the GC acts for a shorter duration of time overall?
A: In the previous article, during boxing, the mov instruction was simply taking the random int value generated and placed by Random.Next within eax and putting it somewhere on the heap. Right before ArrayList‘s Add method was invoked, the address of that object was copied inside a register (edx) before calling the function. In the List<int> sample code (figure 11), the random int value is simply picked up from eax and placed within edx before calling List<int>‘s Add. Therefore, the specific mov that boxing used in the ArrayList sample to copy the random int value to a place on the heap no longer appears.
Q: The discussion here has been around the int value type. But how about type arguments that are reference types? Say List<string>?
A: Good question. Here’s “CLR via C#” again:
“[…]the CLR considers all reference type arguments to be identical, and so again, the code can be shared. For example, the code compiled by the CLR for List<String>’s methods can be used for List<Stream>’s methods, because String and Stream are both reference types. In fact, for any reference type, the same code will be used. The CLR can perform this optimization because all reference type arguments or variables are really just pointers (all 32 bits on a 32-bit Windows system and 64 bits on a 64-bit Windows system) to objects on the heap, and object pointers are all manipulated in the same way.
Jeffrey Richter. CLR via C#
Q: Would a List<string> still be a number of times faster than an ArrayList storing string objects?
A: Based on the previous question, you’ll get about the same performance, as the internal array used by List<string> would contain the references to the individual string objects, in effect just duplicating the behaviour seen with ArrayList. Here’s how things are represented in memory for a sample code that adds string elements to a List<string> instance, right after adding the first 4 elements (code here):
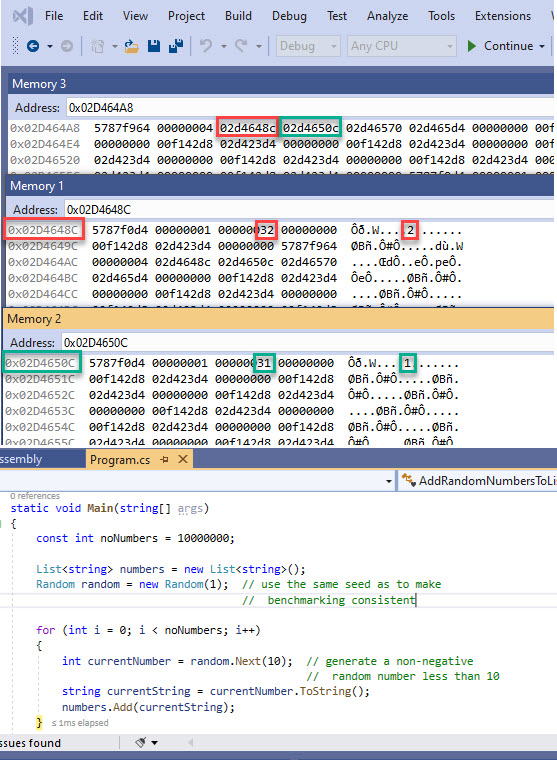
In the top memory window you see the content of the internal string[] array belonging to the List<string> instance. It has a length of 4, as the 5th element hasn’t yet been requested to be added (which would allocate a new array of length 8). Both highlights follow the first and second elements respectively. The first one (red) points to the string “1”, while the second one points to the string “2” (0x31 and 0x32 are characters 1 and 2 respectively, according to the ASCII table). Note the same type object pointer shared by both string objects, as expected – 0x5787f0d4). If you’ll look in video 2 of the previous article, you’ll understand quickly that the same representation is used now as for the ArrayList. Jeffrey Richter’s “CLR via C#” actually compares the performance of a List<string> with an ArrayList of string objects, and the times are quite similar (the beginning of Chapter 12 Generics).
Q: You’re using method and function to refer to the same thing sometimes, eg for List<int>‘s Add. Why?
A: Within C#, the correct term is method, as they’re called against objects. However within assembly language, they are referred to as functions, as the object-oriented programming (OOP) concepts don’t (generally) exist there. There’s a thread about this topic here on Stack Overflow.
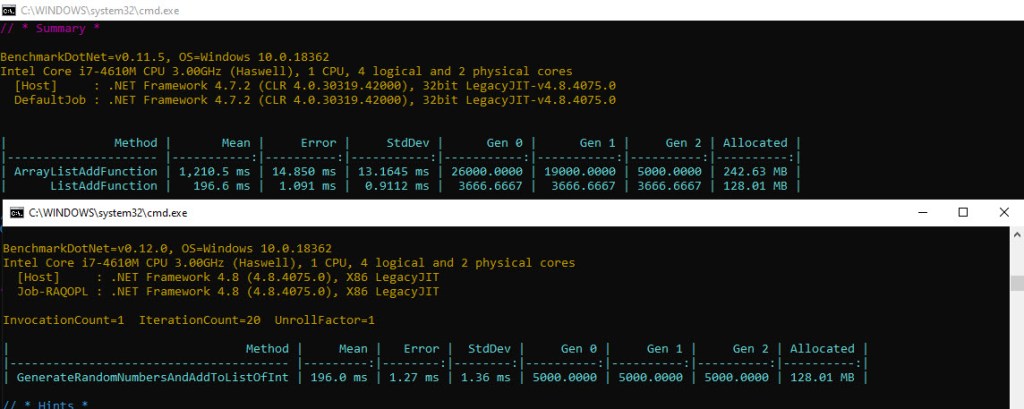
Q: In the original BDN benchmark of ArrayList vs List<int>, whose results are shown both in the first picture of the first article, and in figure 2 of the 2nd article, the number of ops/iteration is not fixed to 1. On my platform I’m seeing BDN deciding on 3 ops/iteration for the the List<int> test method, which would mean there’s no final “cleanup” – as in BDN-induced GCs – after each run of the test method, thus possibly resulting in side-effects due to this “accumulated” runs, as we’ve seen with the ArrayList here. Isn’t this approach misleading?
A: Luckily the GC involved in the List<int> sample is extremely fast, hence the results don’t differ too much between 1 op vs 3 ops/iteration. Here’s a comparison below between the original benchmark using the default ops/iteration (1 for ArrayList, 3 for List<int>) and the one for List<int> using a custom 1 op/iteration. Note almost the same run time on the current platform. Ignore the difference in naming for the List<int> method, as the inner code is exactly the same. Also the BDN version difference (0.11.5 vs 0.12) has no impact on these results.
Q: Why can’t dotMemory show objects on the heap – that is taking a snapshot – without invoking a GC? Why does it have this limitation?
A: It’s not a limitation of dotMemory, but rather of the underlying Microsoft Profiling API it uses (other profilers use it as well). A workaround is to use CLR MD, which doesn’t require any GC to walk the heap. You can find more info in this discussion.
