You just want to modify the content of a few cells in an Excel file stored in Sharepoint Online, using C#. A simple goal. Maybe your experience with Sharepoint APIs is fairly limited, so you spend a while researching. There’s questions over at Stack Overflow, that mention “CSOM”, “REST APIs”, “Graph” and various other cryptic terms, but aside the various limitations with each API, a concise and clear sample proves to be elusive.
TL;DRIf you’re in a hurry to get to the sample code, skip right to it.
The goal of this post is to use Microsoft Graph to read and write to an Excel file stored in Sharepoint Online. As the main focus is getting to use Graph against Sharepoint Online just to get to an Excel file, in terms of operating against the file itself we’ll be content with just reading and updating the value of a single cell.
You’ve ran into it countless times – you open a C# project in Visual Studio and you get to see “Restoring packages for <project_name>.csproj“:
It takes a few seconds usually, then goes away. You continue working for hours, sometimes days, never to encounter the message again. Then – out of the blue – it’s displayed again. There doesn’t seem to be any logic to when this pops up. You might be cloning a Git repository storing a C# project, and moments after, Visual Studio generates the message. Why is there anything to be restored, as we’ve just cloned the full source code for a C# project? Or you decide to use a different target framework for your project, and sure enough the message comes again. Why is this so? Decided to install a NuGet package to your project? – the operation that will be run will be a “package restore”. What is there to restore as you’ve just installed a single package only?
What happens from the moment you launch a .NET Core application, until the very first managed instruction is executed? How do we get from the simple act of running an .exe to having the managed code executing as part of a .NET Core application?
This is what this post sets up to explain in detail, dealing with:
You’re using Azure Functions, and need to decide on the types to use in your C# code in order to implement whatever you’re trying to achieve. In today’s world of powerful cloud computing with sometimes cheap or downright free resources, is it worth pondering over the best type to use ? After all, you get 400,000 GB-s for free per month as part of the consumption plan. And the code within this Azure Function will be just a few dozen lines, tops. Would it matter selecting an efficient data structure for your implementation ?
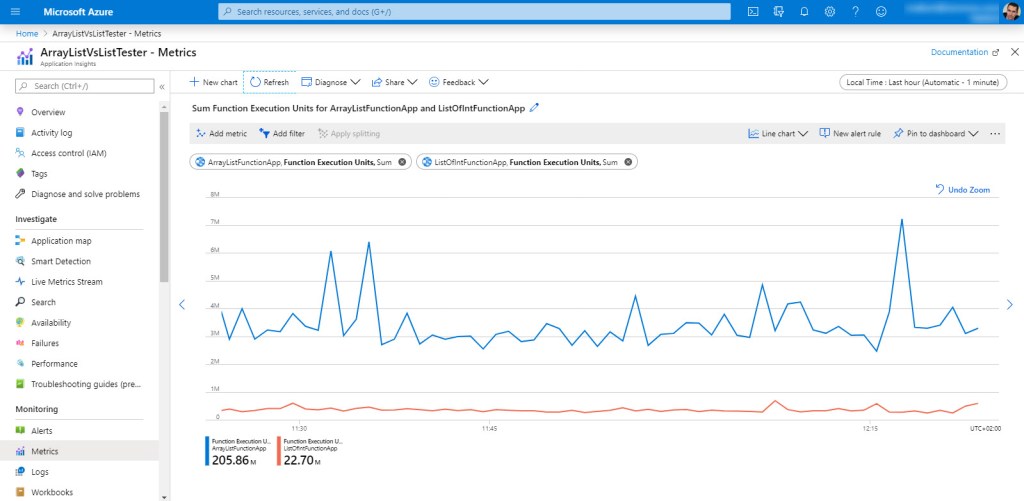
Let’s get specific. Say storing 10 mil numbers is needed each minute as an interim step for further processing. Do you go with ArrayList or List<int> ? Your 2 options below:
Figure 1 – Function execution units for both the ArrayList and the List<int> functions against 10 mil elements, running once each minute
Oh, and you get to pay for the area under the graph of each function. How much does that come to ? Read on.
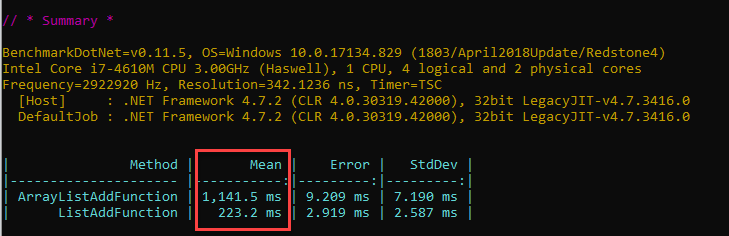
Last time we saw that the code that added random numbers to the ArrayList instance was spending 75% of its total time (1,141.5 ms) just doing GC. Computing the other 25%, representing the actual work, gives out about 285 ms. But how can this be, since the time the List<T> code takes – including its own GC activity – is 223 ms? Is the List<T> implementation really that much efficient, that even with GC activity, it manages to complete faster that the actual time spent doing work in the case of the ArrayList one? Are generics just that magical?
In the first part of this 3-article series, we’ve found to our astonishment that code based on ArrayList performs a whole lot worse than the same one using List<T>.
In order to understand why this is so, we’ll break up the code in smaller parts, see what these involve under the hood and how much time each takes. We should then be able to pinpoint the operation(s) that have the major contribution to the difference in performance. We’ll do this for both structures, and start with ArrayList in this post.
Consider consuming a series of bytes and storing them in memory for future processing. Let’s take the code snippet below:
const int noNumbers = 10000000; // 10 mil
ArrayList numbers = new ArrayList();
Random random = new Random(1); // use the same seed as to make
// benchmarking consistent
for (int i = 0; i < noNumbers; i++)
{
int currentNumber = random.Next(10); // generate a non-negative
// random number less than 10
numbers.Add(currentNumber); // BOXING occurs here
}
Is this code good from a performance standpoint ? Not really, it’s actually quite appalling. Take a look at the running times for the ArrayList snippet above and, for the same exact code, but which uses List instead:
This makes the ArrayList code more than 5 times slower than the List one.
Boxing happens in the first case, but not in the second. This mechanism explains most of the performance difference seen above. Intrigued ? Read on.
Ever wondered how many methods with a specific signature are contained within an assembly ? Say, how many methods that take at least one parameter of type object are in all the types marked as public within the mscorlib.dll assembly.
(TL;DR: I’m in a real hurry, and need the code to do this really quick ! Where is it ? You’ll find it towards the end of the article, here)
mscorlib.dll is a somewhat challenging example, since this assembly contains all the core types (Byte, Int32, String, etc) plus many more, each with scores of methods. In fact, the types within are so frequently used that the C# compiler will automatically reference this assembly when building your app, unless specifically instructed not to do so (via the /nostdlib switch).
You’ve just created a Console app in the latest Visual Studio, and wrote some C# code that allocates some non-negligible quantity of memory, say 6 GB. The machine you’re developing has a decent amount of RAM – 16GB – and it’s running 64-bit Windows 10.
You hit F5, but are struck to find the debugger breaking into your code almost immediately and showing:
Figure 1 – Visual Studio breaking into an exception
What’s going on here ? You’re not running some other memory-consuming app. 6 GB surely should have been in reach for your code. The question that this post will set out to answer thus becomes simply: “Why do I get a System.OutOfMemoryException when running my recently created C# app on an idle, 64-bit Windows machine with lots of RAM ?“.
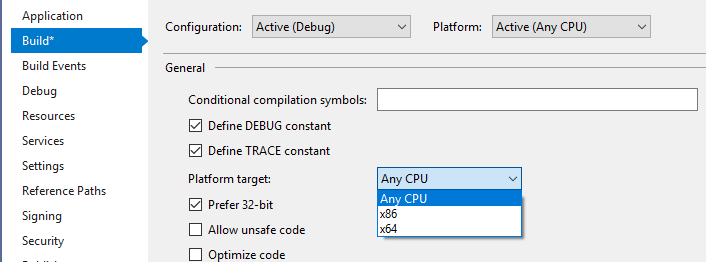
TL;DR (small scroll bar => therefore I deduct a lot of text => I’ve got no time for that, and need the answer now): The default build settings for Visual Studio limit your app’s virtual address space to 4 GB. Go into your project’s Properties, go to Build, and choose Platform target as x64. Build your solution again and you’re done.
Not so fast ! Tell me more about what goes on under the hood: Buckle up, since we’re going for a ride. First we’ll look at a simple example of code that consumes a lot of memory fast, then uncover interesting facts about our problem, hit a “Wait, what ?” moment, learn the fundamentals of virtual memory, find the root cause of our problem then finish with a series of Q&A.
You’re working with assemblies in .NET, and you have to load one of these assemblies in your code. Trouble is that the code you’re currently running – and which is getting ready to load that assembly – has been built for the x64 architecture, and the assembly you want to load was built for x86. You try to load the assembly – either explicitly or by calling one of the methods in it – and sure enough, you run into the following exception:
System.BadImageFormatException: ‘Could not load file or assembly ‘x86_Assembly’ or one of its dependencies. An attempt was made to load a program with an incorrect format.’
Ok, so clearly this combination whereby an x86 assembly gets loaded in x64 code doesn’t work. But what about the rest ? There are 3 options in the Platform target drop down, and the Prefer 32-bit option becomes active once the Any CPU is selected, thus yielding a total of 4 possible targets.
Figure 1 – Visual Studio’s Build page
Those 4 targets can equally apply to the assembly that’s being loaded, as well as to the code that’s loading it. All in all, 16 possible combinations. The question that this post sets out to answer is “Which out of these 16 work, and which don’t ?“.
TL;DR (I’ve got no time for your nonsense, just tell me the answer): The table of truth will tell you. If you make sure the assembly you’re loading is built using AnyCPU or AnyCPU+Prefer 32-bit, you’ll have no issues, regardless of the platform target you’re using for the “host” process, aka the code that loads the assembly. “Explicit cross-bitness”, as in loading x86 assembly in x64 code or the other way around won’t work. Having the same platform target for the code consuming the assembly and the assembly itself will always work. For “How about loading assemblies in an AnyCPU host process” or “Why is this ?” you’ll have to read on.
Give me the whole story (I’ve got plenty of popcorn, carry on): we’ll start by defining what an assembly is, what does it mean to load an assembly and how it can be done, present an example and analyze the outcome, and in the end go deeper and draw some conclusions. We’ll finish with a Q&A session.